Lumus几何波导技术赋能美国海军Holochip H50 AR设备 ( 映维网Nweon 2025年04月08日 )据报道,几何(反射)波导技术开发商 Lumus 已获选成为Holochip全新H50 AR设备的光学引擎合作伙伴,并将致力... 1 年前
Steam好评如潮游戏《围攻》将5月登陆Meta Quest ( 映维网Nweon 2025年04月08日 )根据官方消息,Steam热门游戏《围攻》将于下个月提供面向 Meta Quest 的VR版本,具体时间待定。 在 ... 1 年前
Meta与汉莎航空合作成果显著,Quest 3机上娱乐将发展更多航司 ( 映维网Nweon 2025年04月08日 ) Meta 曾在2024年宣布与德国汉莎航空合作,为乘客提供 Quest 3头显。在日前发布的一篇博文中,团队表示项目... 1 年前
格拉斯哥大学研发面部表情XR控制系统,实现97%准确率的无手柄交互 ( 映维网Nweon 2025年04月08日 )为了帮助残障人员拥抱XR技术,苏格兰格拉斯哥大学和瑞士圣加仑大学正在研究如何仅通过面部表情来精确控制计算机... 1 年前
苹果发布Immersive Video Utility工具,支持Vision Pro多设备同步播放 ( 映维网Nweon 2025年04月08日 ) 苹果 日前发布了一个名为Apple Immersive Video Utility的全新应用程序,主要用于在Mac端管理沉浸式视频库。... 1 年前
传Vision Pro 2进入量产阶段,供应链确认蓝思科技/长盈精密供货 ( 映维网Nweon 2025年04月08日 )界面新闻财经号电厂引述多个独立信源称, 苹果 第二代XR头显产品(或名为 Vision Pro 2)已进入规模生产阶... 1 年前
《维度双重转移》将在Quest平台上进入抢先体验,并发布首个付费DLC。 Owlchemy Labs宣布其免费社交游戏《Dimensional Double Shift》结束公开测试,并推出首个收费DLC“Hexas”,带来全新德克萨斯州风格的维度。玩家将在滑稽的宇宙中为外星顾客修理汽车和食物,新的DLC包含50多种Hexas主题装饰品,玩家可以打扮成牛仔或沙漠公路勇士。首席执行官Andrew Eiche表示,Hexas是一个重要里程碑,带来全新体验。此外,游戏更新将加入“房间浏览器”功能,方便用户创建和加入公共多人房间。Hexas维度包定价5美元,仅在Horizon Store上提供。 1 年前
Meta发布Quest App产品页优化指南:精准设定期望提升用户留存 ( 映维网Nweon 2025年04月08日 ) Meta 的增长洞察Growth Insights旨在帮助开发者提高用户粘性、留存率和盈利。作为希望从Meta Horizon Store... 1 年前
开发实战:使用PCA API访问Meta Quest的摄像头 ( 映维网Nweon 2025年04月08日 )开发者现在已经可以访问Meta Quest头显的摄像头,但具体的操作是怎样的呢。下面这篇来自Skarredghost的博文将逐... 1 年前
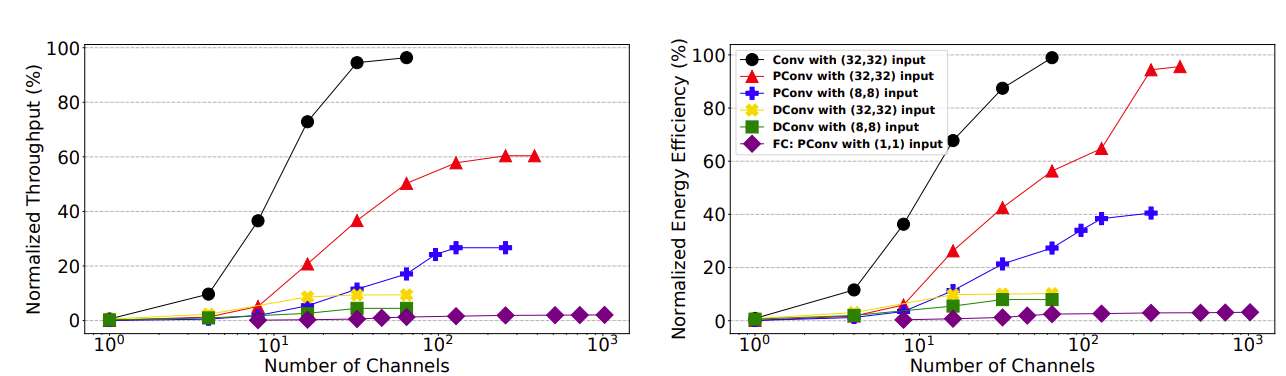
Meta等联合开发H4H-NAS框架,提升AR/VR边缘AI能效 实现了显著(高达1.34%)的top-1精度提升 ( 映维网Nweon 2025年04月08日 )低延迟和低功耗边缘AI对于虚拟现实和增强现实应用至关重要。最近的... 1 年前

 Insider
Insider