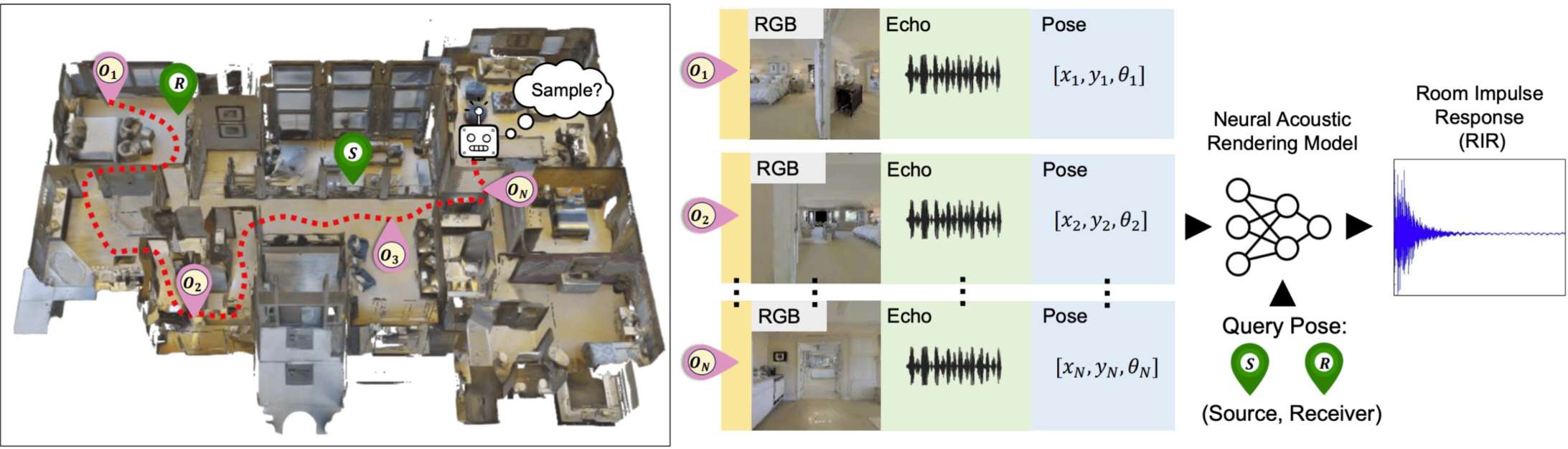
得克萨斯大学为AR/VR提出有效估计和模拟环境声学的新方法ActiveRIR
一项新的研究指出,得克萨斯大学奥斯汀分校的研究人员提出了一种利用强化学习生成高质量声学模型的方法,该方法能够在VR或AR中生成真实世界环境的逼真模型。传统的声学建模方法需要大量音频样本,不仅会消耗设备电池,而且需要很长时间来进行估计。该团队提出了一种名为ActiveRIR的新方法,通过使用主动声学采样,通过在未知3D环境中移动,并决定在哪里收集视听样本,来解决这些问题。ActiveRIR模型由两个主要部分组成:视听采样策略和声学估计模型。这两个部分相互合作,最终生成逼真的环境声学模型。团队对该方法进行了一系列测试,并发现它表现出色,效果优于许多现有的声学估计技术。研究人员表示,他们的方法具有足够的通用性,可以支持多种不同的声学估计模型。这项研究的结果有望帮助制作更真实的VR和AR内容,能够逼真地再现特定3D场景的声音。未来研究将在更广泛的环境中进行测试,以探索它在真实室内空间中的应用。