
(
映维网
2019年10月29日
)计算机视觉应用程序通常需要处理多帧图像,入通过视频捕获的图像。这个处理过程最重要的其中一个方面是,能够在对象移动以及视口更改时识别和追踪对象。从机器人视觉处理和自动驾驶起到,到安全录像和增强现实,这种功能的用例几乎无穷无尽。
尽管这对于功能强大的移动处理器而言似乎微不足道,而且我们人类可以轻松实现,但要在数字世界中重现这一功能确实不易。高通的Felix Baum日前
撰文
向我们介绍这一领域所面临的挑战,以及潜在的解决方案。下面是映维网的具体整理:

1. 运动帧的挑战
分析视频帧提出了大量的挑战,其中很大一部分是由于给定场景涉及的变量数十分巨大。以下是开发对象检测与追踪应用程序时应考虑的挑战:
幸运的是,社区已经开发了一系列的方法,而且由于边缘处理能力的提高,现在大量的方法已经变得可用。
2. 方法
在追踪对象的移动之前,我们需要了解对象的外观,同时要记住对象的外观可能会随着帧而变化。应对所述挑战的第一步是开发视觉外观模型,如下图所示
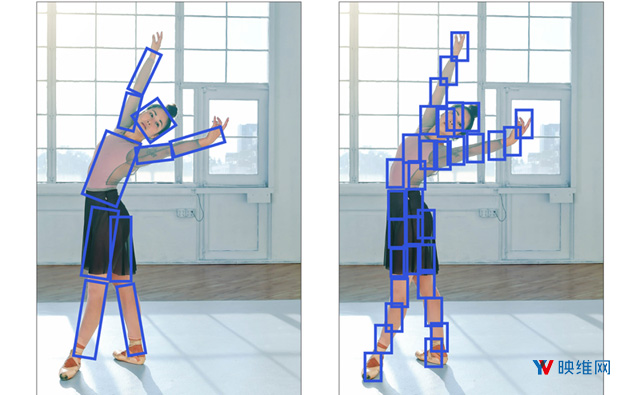
它由将用于识别对象并将其与唯一标识符(如对象ID)相关联的算法组成。负责这一操作的组件通常称为分类器,其作用是将图像数据块作为输入,并产生输出图像包含已识别对象的概率。
一旦有了识别对象的机制,下一步就是确定运动模型(即本地化)。它由确定对象在多帧中的位置的算法组成,并且可以包括预测未来位置的功能。
视觉外观和运动模型是一般对象追踪过程的基础,这个过程通常涉及确定对象的初始状态及其外观,估计其运动并计算其位置。这种算法统称为追踪算法,其中包括外观模型和运动模型的计算。在特定情况下,两个模型的计算相互馈送以得出结果。
3. 追踪算法的分类
在研究特定算法之前,重要的是要知道现有追踪算法的一般分类。
4. 方法和算法
随着对象追踪在近年来成为了视觉处理中的热门话题,社区正在不断开发各种方法和算法。下面我们将列举多个算法,从而帮助你对进一步了解计算机科学领域的广度和深度。
GORURN等基于卷积神经网络的离线追踪器首先针对数千个视频进行训练,并旨在处理单对象追踪。接下来,它确定对象在视频第一帧的边界框,并在随后的帧中进行追踪。尽管它不处理对象遮挡,但可以处理视点,光照和对象形状的变化。
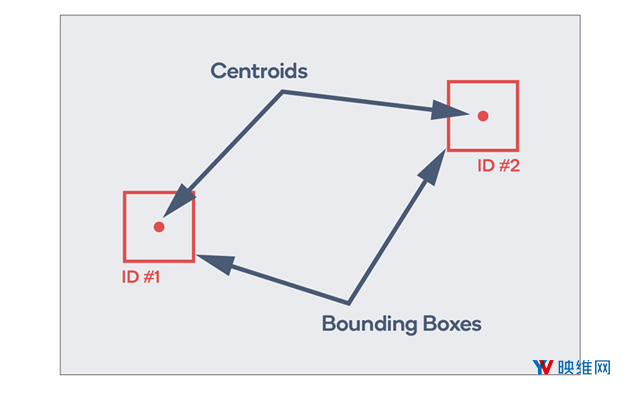
质心追踪(Centroid Tracking)会在每一帧中获取对象的边界框。可以使用任何数量的算法(如上述基于卷积神经网络的方法)来计算边界框。然后,质心追踪将计算边界框的中心,并为其指定ID。在每个后续帧中,算法会尝试确定新计算的边界框是否可以与前一帧中标识的边界框相关联。如果可以建立关联,则计算新位置,从而实现对象的追踪。
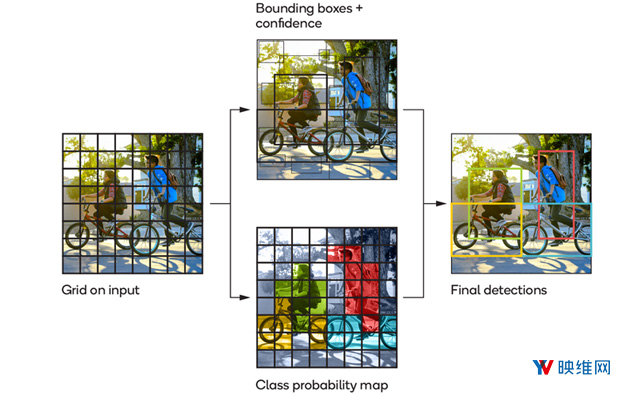
You Only Look Once (YOLO)追踪是一种深度学习方法,它将帧划分为多个区域,并应用神经网络预测每个区域的边界框和概率。接下来,它通过预测概率对边界框进行加权以识别对象。如果发现对象标识匹配的概率,则表明在给定的一组帧中实现了对象追踪。 如下图所示。
当然,你可以找到许多其他算法,但上面列举的算法可以向你展示问题是有非常多的不同解决方案。
5. 移动端的对象追踪
高通对对象陌生并不陌生。我们的
Qualcomm
Computer Vision SDK包括用于检测和追踪对象,特征(如面容和文本),以及运动的API。Qualcomm Neural Processing SDK则可以用于执行AI算法,而Machine Vision SDK则适用于机器人和自动驾驶汽车应用。另外,你可以关注包含用于数学运算的Qualcomm Math Library。当然,我们的高通晓龙移动平台可以通过Qualcomm Hexagon DSP处理器,Qualcomm Spectra图像信号处理器和Qualcomm Adreno GPU等功能来执行对象检测和追踪算法。
6. 总结
对象检测和追踪是计算机视觉中的关键组件,因为它们可以帮助实现从录像分析到自动机器人等一系列的用例。就如同应用程序几乎是无穷无尽一样,为应对挑战而开发的巧妙方法和算法同样如此。
0