(映维网Nweon 2025年06月05日)尽管头显可以通过语音输入来控制,但用户在公共场合对着可穿戴设备大声说话或以类似方式控制可穿戴设备会感到不舒服。另外,如果在附近有人,其他人的声音可能会无意中影响头显的功能。
在一份专利申请中,谷歌就提出了一种特别的方法,利用鼻音来控制头显。作为说明,鼻音是声带振动 + 鼻腔共鸣的辅音,广泛存在于世界语言中。汉语和英语中的鼻音均为浊音。
团队指出,鼻音的检测和处理为控制头显提供了一种直观和低费力的输入方法。例如,用户可以使用“Mm-hm”、“Nuh-uh”和“Hmm?”。通过这种鼻音辅音,用户可以在一天中多次自然发出的声音来实现对头显的完全免手控制。即使是闭着嘴,用户都可以谨慎地发出鼻音。
在一个实施例中,用于控制头显的输入法可允许检测诸如在诸如“mmm-MMM”、“NNN-nnn”和“mmMM”等发声中存在的细微发声片段,例如鼻音。检测到的鼻音可以映射到控制命令,并对应于设备操作,如选择、返回、唤醒等。
为了谨慎起见,选择的发声交互集可以安静地执行,不需要张嘴。在语音学中,这属于一组称为鼻辅音的音素:[n], [η]和[m]。
在一个实施例中,可通过接到头显控制器的惯性测量单元(IMU)检测鼻音。IMU不用于检测任何类型的语音命令,但可用于帮助区分用户鼻音或周围其他人发出的其他声音。IMU可用于检测由鼻音引起的极低频振动,例如小于1500Hz。
为了更好地检测低频振动,IMU可以放置或集成在头显框架的近端。振动是由用户产生,可以与环境噪声隔离。
在一个实施例中,用户产生鼻音的上下文可用于将鼻音识别为命令。上下文可以根据预测输入数据确定。例如,如果在头显中产生供用户查看的提示,并且用户在提示的阈值时间段内用鼻音进行响应,则可以将鼻音识别为命令。
图1示出用于控制头显 112的鼻音识别过程。在这个例子中,用户戴着智能眼镜形式的头显 112。
如上所述,用户可以产生鼻音来控制头显 112。当使用者的口腔轨道(嘴)完全闭合时,发声的鼻辅音产生音素,迫使空气通过鼻子。唇部或肺泡114可分别发出音素[m]和[n]。如果使用者选择使用鼻音,这意味着声带在振动,产生低于1500赫兹的低频声波。由于音素产生清晰的低频声音(即振动),可通过用户头部传输头显 112框架,所以可以通过接到集成在头显控制器102的IMU110检测振动。
与鼻音相比,典型的语音发声(例如,口语单词)对大多数用户来说具有15 kHz的高频,而IMU 110可能无法准确检测到。所以,使用IMU 110可以将典型的语音发声与鼻音区分开来。
一个或多个诸如鼻音18的鼻音可以用作一组控制命令来导航头显 112的头显用户界面。各种相关的鼻音可用于控制头显 112。
例如,“Mm-hm”可以用来选择一个肯定的选项(例如接听电话、打开通知等的是/否)。“Nuh-uh”则可用于选择否定选项(例如拒绝电话,清除通知等)。
为了谨慎起见,选择鼻音的发声交互可以由用户安静地、不张嘴地进行。
在一个实施例中,可以将一个或多个麦克风与IMU 110结合使用,以提高检测一个或多个鼻音的准确性。一个或多个麦克风可以表示为头显模块120的音频传感器103。一个或多个麦克风可用于识别上下文。
例如,IMU 110可用于检测与鼻音相关的振动。所述候选振动可最初识别为鼻音,并且所述音频传感器103可用于检测与所述候选振动同时的声音,以确认所述候选振动是鼻音。
在一个实施例中,可以将一个或多个图像传感器与IMU 110结合使用,以提高检测一个或多个鼻音的准确性。一个或多个传感器可以表示为头显模块120的图像传感器104。一个或多个图像传感器可用于识别上下文。
例如,IMU 110可用于检测与鼻音相关的振动。所述候选振动可最初识别为鼻音,所述图像传感器104可用于检测与所述候选振动同时捕获的图像,以确认所述候选振动是鼻音。
在一个实施例中,可以将一个或多个麦克风(例如,音频传感器103)、一个或多个图像传感器(例如,图像传感器104)和/或一个或多个眼动追踪器(例如105)与IMU 110结合使用,以提高检测一个或多个鼻音的准确性。一个或多个麦克风和一个或多个图像传感器可用于识别上下文。
例如,IMU 110可用于检测与鼻音相关的振动。候选振动可最初识别为鼻音,并且音频传感器103和图像传感器104可用于分别检测与候选振动同时捕获的声音和图像,以确认候选振动是鼻音。眼动追踪器105可用于确定用户正在查看显示在头显112的显示器。所以,鼻音可以解释为与提示相关联的头显控制命令。
在一个实施例中,与鼻音相关联的振动可以作为一种选择方法(例如,类似于鼠标点击),而不对应于用户界面中的提示。换句话说,与鼻音相关的振动可以作为一种选择方法,而不对应于用户界面中单词的发音。因此,鼻音可以代替一个典型的单词作为输入选择方法。
例如,用户界面可以在用户界面中显示带有“yes”或“no”字样的提示。像“Mm-hm”这样的鼻音可以用来选择“是”,而像“Nuh-uh”这样的鼻音可以用来选择“否”。因此,用于选择与是/否用户界面相关的输入选项之一的声音和/或振动将不对应于单词“是”或“否”。
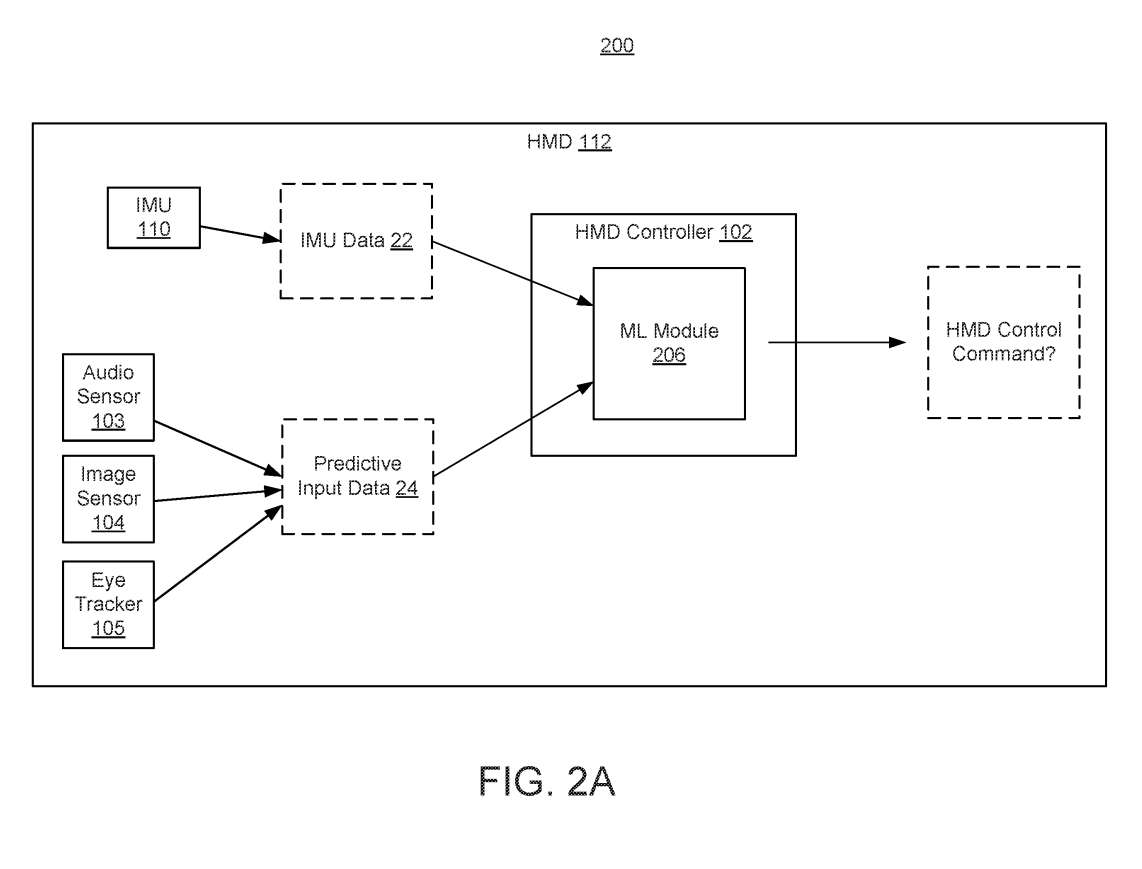
图2A示出头显112,其中包括ML机器学习模块206,并配置为处理IMU数据22(如上所述)和预测输入数据24以确定与鼻音相关的振动是否是头显控制命令。
例如,一个或多个发声之间或附近的鼻音可用于确认鼻音作为头显控制命令。例如,可以在振动之前或在振动之后通过麦克风检测用户的发声。换句话说,振动可以伴随着与用户发声相关的声音,并可以用来确定振动是鼻音。发声的上下文或内容可以用来确认发声的鼻辅音是否是头显控制命令。
作为一个具体的例子,可以检测到向头显提供指令的发声句子。如果振动与鼻音相关,则可以用来确定该振动是头显控制命令。在一个实施例,可以单独使用振动(由IMU 110检测)来确定鼻音,而无需使用音频传感器103进行声音检测。
另一个例子,在一对发声之间的鼻音可以用来确认鼻音作为头显控制命令。例如,可以通过麦克风在振动之前和在振动之后检测到人的发声。人发出的声音的上下文或内容可以用来确认用户发出的鼻音是否是头显控制命令。
作为一个具体的例子,可以检测到从一个人对用户说话时发出的发音句子。与发声的鼻辅音相关的振动可以用来确定该振动不是头显控制命令,而是直接与用户说话的人进行交流。
在一个实施例中,当使用麦克风检测到与人的对话时,可以使用与相关的鼻音来确定该振动不是头显控制命令,而是指向与用户说话的人的通信。这时候,发声的鼻辅音不解释为头显控制命令。
如图2A所示的ML模块206可以执行一个或多个ML模型来处理IMU数据22和预测输入数据24。ML模型可用于处理IMU数据22和预测输入数据24的一种或多种类型。ML模型可以在IMU数据22和预测输入数据24的一种或多种类型进行训练。
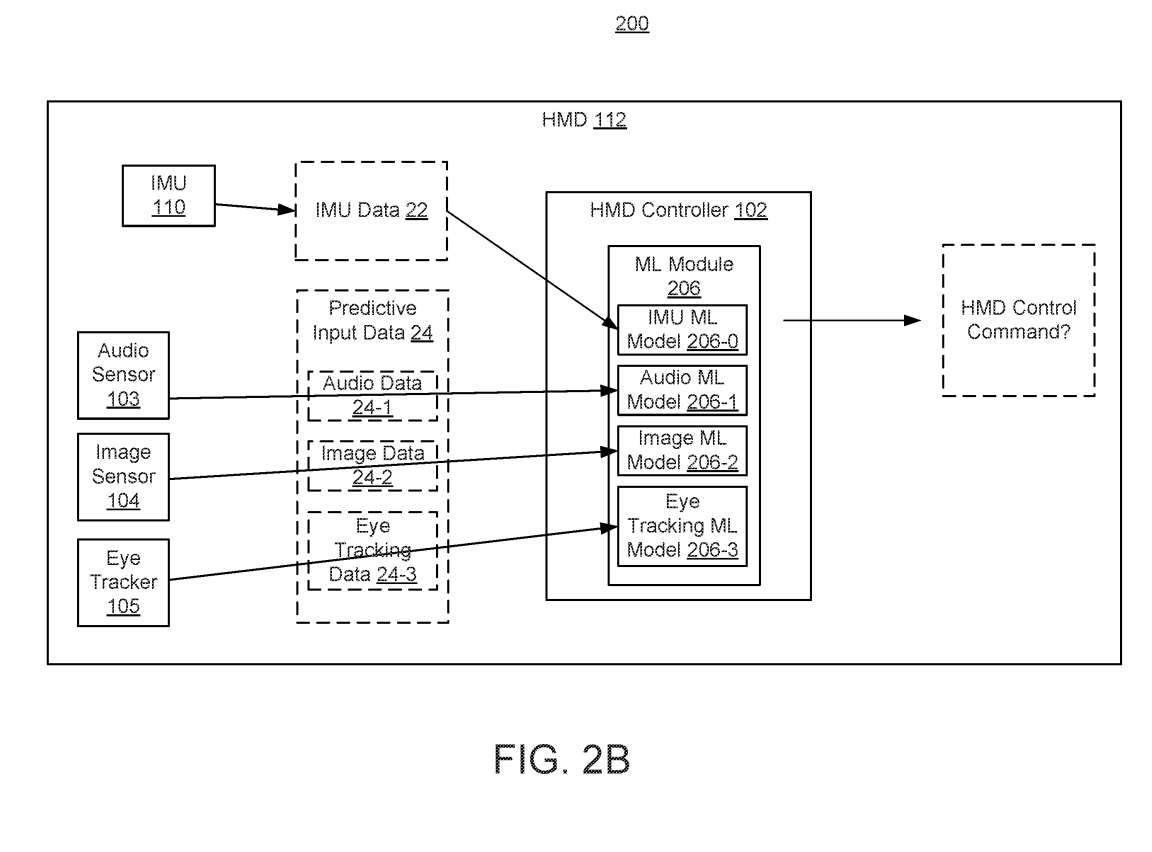
作为另一个例子,可以使用IMU ML模型来处理IMU数据22。如图2B所示,IMU ML模型206-0可用于处理IMU数据22。音频数据24-1可以由音频ML模型206-1处理(例如分类),图像数据24-2可以由图像ML模型206-2处理,眼动追踪数据24-3可以由眼动追踪ML模型206-3处理。
可以将头显控制器102配置为使用一个或多个规则或启发式方法组合分类数据。每个ML模型都可以用来生成与模型相对应的分类数据。例如,由IMU ML模型206-0产生的IMU分类数据、由音频ML模型206-1产生的音频分类数据、由图像ML模型206-2产生的图像分类数据和/或由眼动追踪ML模型206-3产生的眼动追踪分类数据可以使用一个或多个规则组合,以确定与鼻音相关的振动是否与头显控制命令相关。
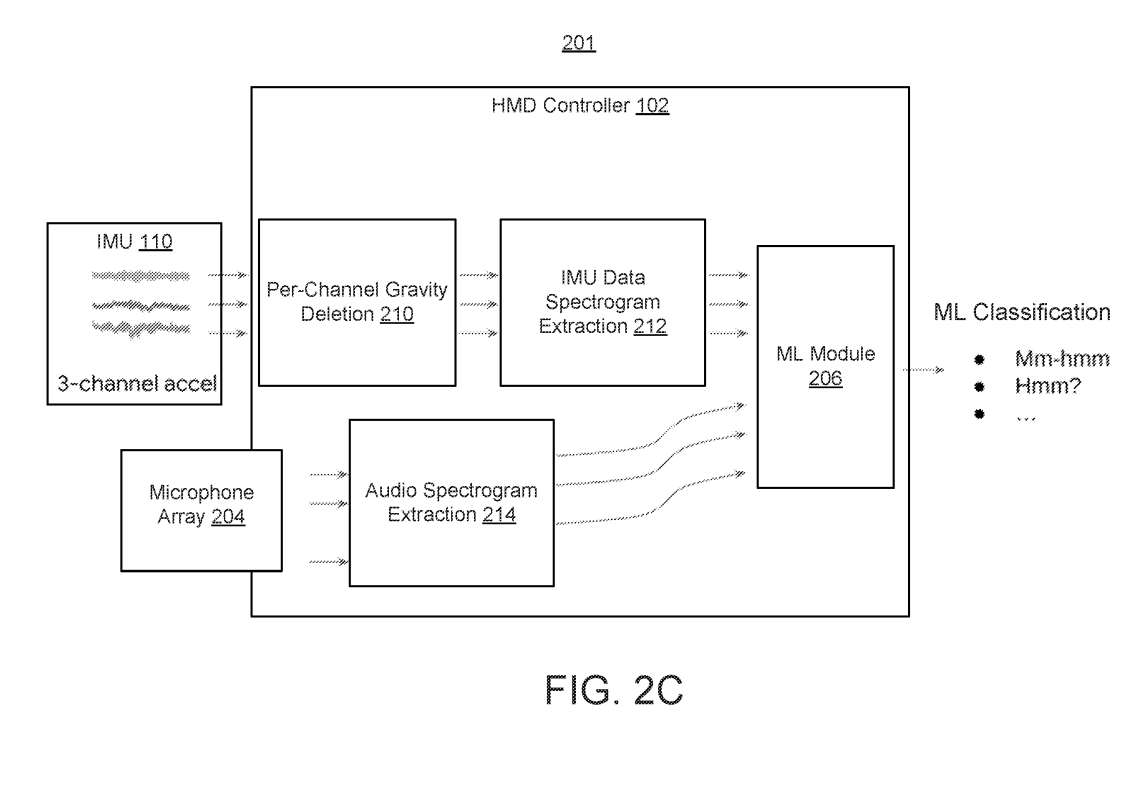
图2C说明了相关架构。头显控制器102可以对模块210的原始IMU数据执行每通道重力删除,以补偿重力的影响,以便获得准确的测量。然后,头显控制器102可对模块210在模块212处输出的数据进行IMU数据频谱图提取。原始IMU数据在通过模块210和212进行处理之前,可由头显控制器102的处理器转换为数字格式。然后,可以将提取的频谱图数据提供给执行模型的机器学习(ML)模块206,以确定与频谱图数据对应的头显控制命令。
频谱图(包括音频和加速度计)可以包含有关频率、随时间变化等信息。频谱图提取可以包括分析IMU数据和/或音频数据的特征嵌。频谱图提取可用于从频谱图中提取特征嵌入,例如如图2D所示。
图2D示出示例谱图280。具体来说,图2D显示了对数谱图。图2D显示了Y轴的频率数据(单位为Hz)和X轴的时间(单位为秒)。以分贝(dB)为单位的声强在这张声谱图280中以阴影级表示。与鼻音相关的IMU数据,由于是时间相关的数据,可以用谱图表示。
可以使用ML模型处理来自IMU 110的IMU数据和/或来自麦克风阵列204的音频数据。ML模型可以结合IMU数据和音频数据训练的模型来处理IMU数据和音频数据。
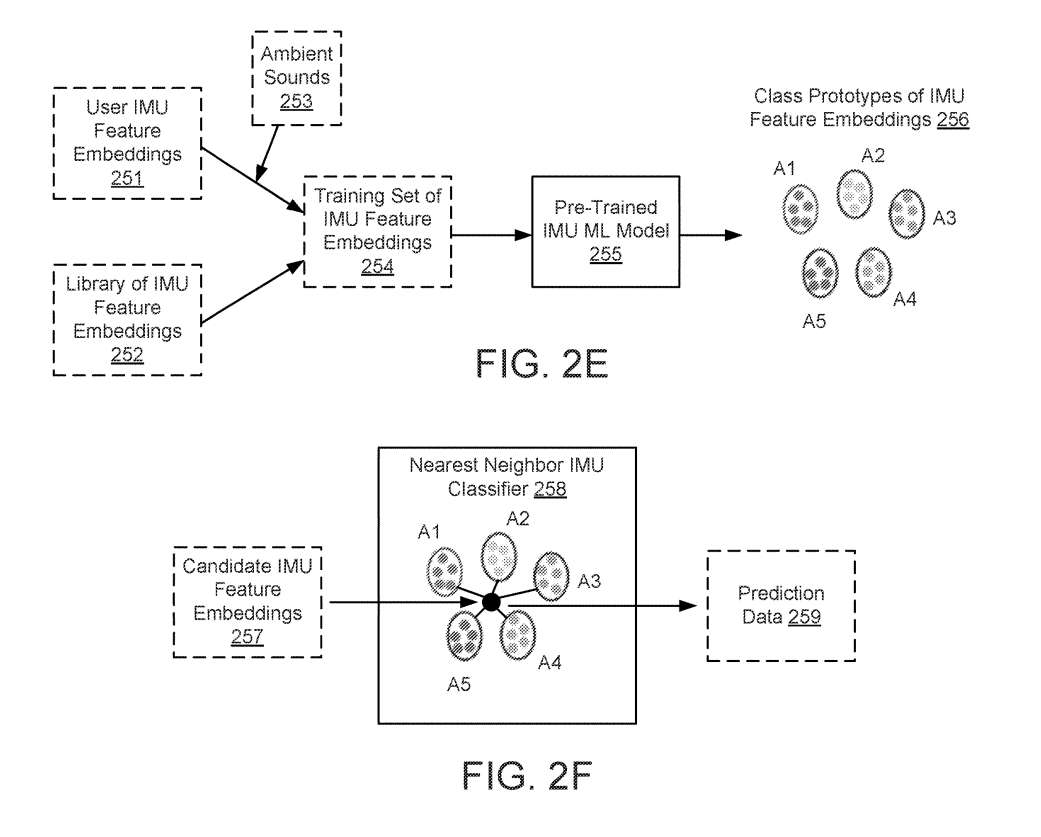
图2E展示了使用预训练的IMU ML模型255生成一组IMU特征嵌入256。IMU特征嵌入256的类原型是被分类为代表特定鼻音的特征嵌入。IMU特征嵌入256的类原型一旦产生,就可以用于图2E所示的分类器。
IMU特征嵌入254的训练集包括IMU特征嵌入251库和用户IMU特征嵌入252的组合,以便IMU特征嵌入254的训练集可以针对特定用户进行定制。换句话说,预训练的IMU ML模型255,结合IMU特征嵌入库252和用户IMU特征嵌入库251,并用于定制鼻音的ML处理(例如分类)。
图2F说明了配置为对候选IMU特征嵌入257进行分类的分类器258。258可以是在ML模块206中执行的ML模型。候选IMU特征嵌入257可以是从IMU频谱图中提取的IMU特征嵌入,IMU频谱图表示鼻音,使用来自IMU的加速度计数据响应鼻音的振动产生。
在一个实施例中,候选IMU特征嵌入257通过识别哪个IMU特征嵌入的类原型与候选IMU特征嵌入257最匹配来分类。这可以通过计算特征嵌入空间中的欧氏距离来完成。
分类器258的结果表示为预测数据259。预测数据259可以包括候选IMU特征嵌入257与IMU特征嵌入256的类原型之一匹配的置信水平。换句话说,候选IMU特征嵌入257的分类可用于产生预测数据259。
例如,预测数据259可以包括候选IMU特征嵌入257与IMU特征嵌入A2的类原型匹配的90%置信水平。预测数据259可用于确定头显控制命令,预测数据259提供候选IMU特征嵌入257与特定的鼻音相关联的预测。换句话说,候选IMU特征嵌入257的分类可用于确定鼻音和/或头显控制命令。
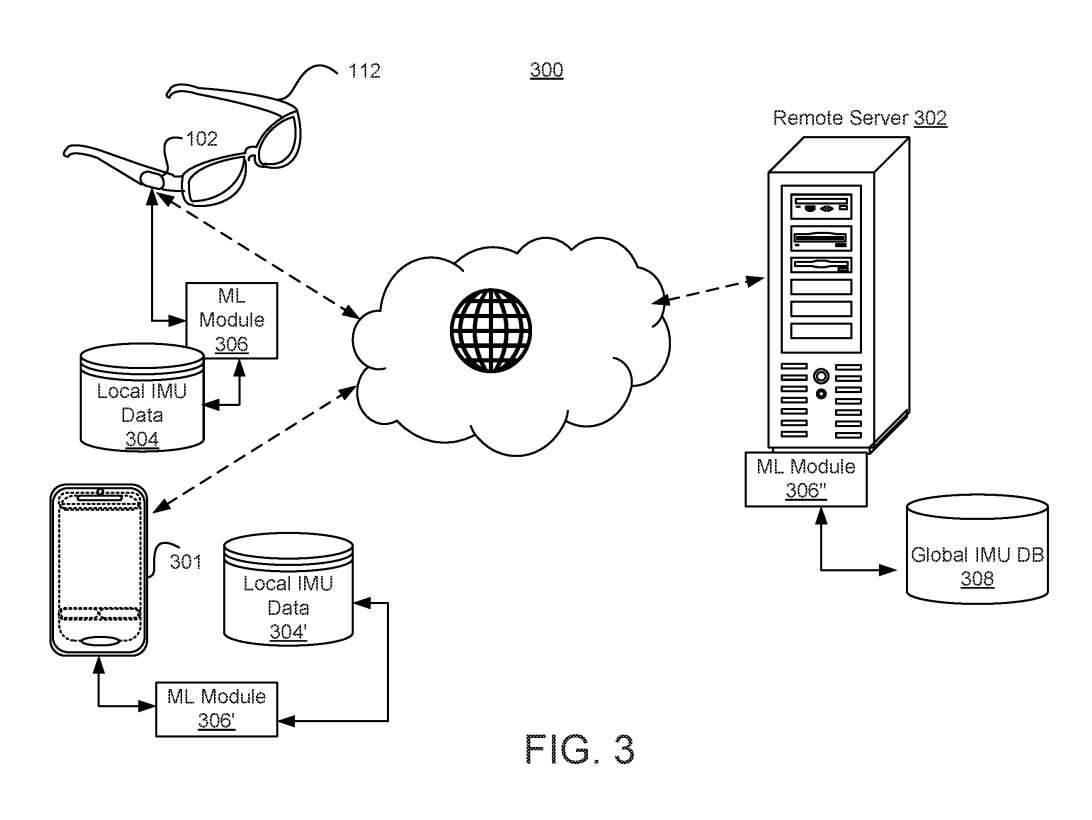
图3示出网络300。头显控制器102可以接收IMU数据。头显控制器102可向执行模型的ML模块306提供IMU数据,以确定与表示IMU数据相对应的头显控制命令。ML模块306可由头显控制器102执行,并可使用本地IMU数据304。
在至少一个实施例中,ML模块306’可以在通过无线网络连接到头显112的移动设备301执行。在至少一个实施例中,移动设备301可以通过无线点对点连接接到头显 112。
在又一实施例中,ML模块306″可以在通过无线网络连接到移动设备301的远程服务器302实现。这种安排可能允许ML模块306″使用全局IMU数据308进行监督机器学习。例如,多个头显用户记录的各种鼻音样本可由远程服务器302聚合并存储在全局IMU数据库308中。
这样,如果头显控制器102接收到的鼻音没有使用存储的本地IMU数据304和304’在本地识别,则可以将鼻音与头显控制命令对应的更大的历史IMU数据样本池进行比较。机器学习模型可能包括使用原型网络或迁移学习的校准。
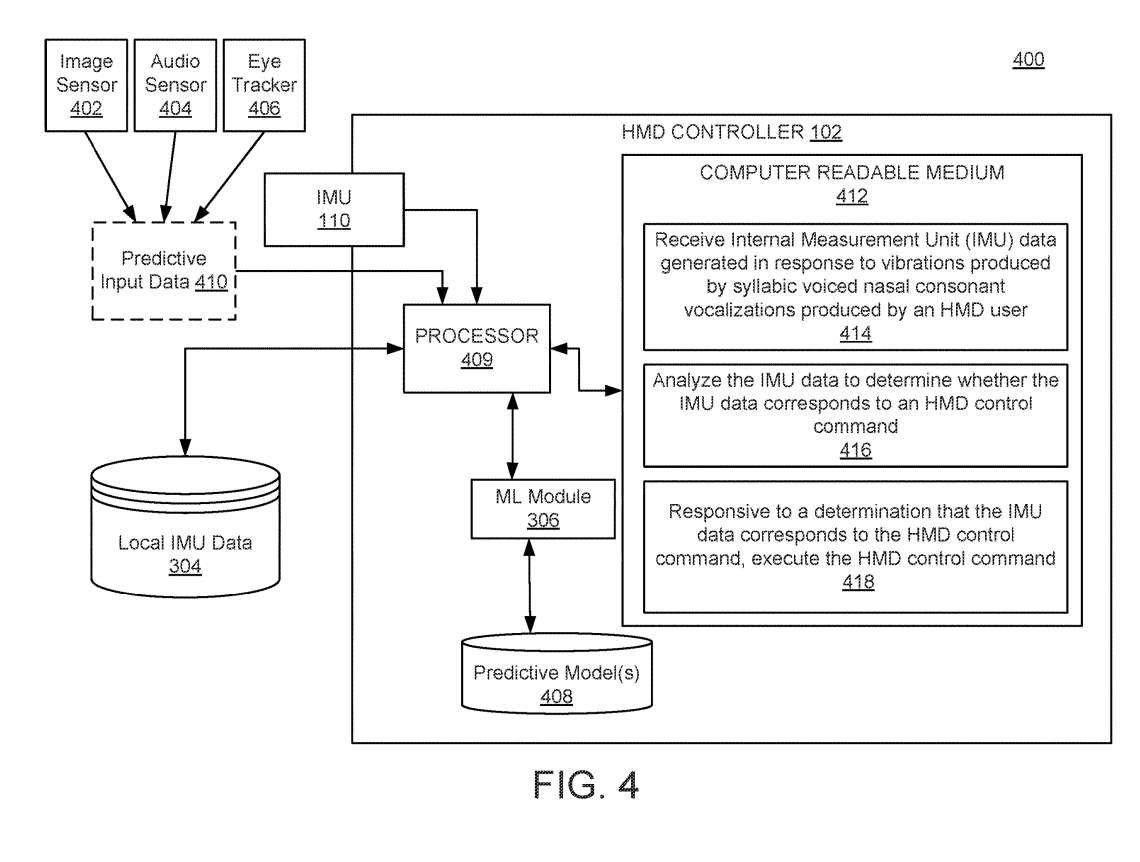
图4示出用于微语音手势识别的示例系统400。
处理器409可以执行配置为生成预测模型408的ML模块306,以确定与从IMU 110和从音频传感器406接收的数据相对应的头显控制命令。
ML模块306可以使用预测输入数据410,包括眼睛检测数据。换句话说,如果头显用户看着头显屏幕的“选择”按钮并发出鼻音,则很可能头显用户正在尝试触发“选择”动作。
在一个实施例中,预测数据410可与IMU 110数据和音频传感器404数据组合,用于训练预测模型408。头显的一个或多个麦克风可以检测头显用户何时与另一个人交谈,所以不打算用浊音鼻音来控制显示。可以使用图像传感器402来生成预测数据410。
相关专利:Google Patent | Controlling head-mounted devices by voiced nasal consonants
名为“Controlling head-mounted devices by voiced nasal consonants”的谷歌专利申请最初在2022年7月提交,并在日前由美国专利商标局公布。