(映维网Nweon 2025年04月03日) Ambisonics作为一种灵活的空间音频格式,可用于任何所需的扬声器布局,并广泛用于XR环境的音频,因为它可以提供一种简单有效的方法来操纵录制或合成声场,例如,通过波束成形到不同的方向。
大多数传统的Ambisonics都为低阶,比如一阶First-Order Ambisonics(FOA)。在渲染FOA时,空间分辨率非常低。尽管高阶空间分辨率增加,但在音频捕获时可能需要非常多的通道。例如,捕获三阶Ambisonics需要16个通道,而捕获五阶Ambisonics需要36个通道。
捕获36个通道可能在计算和物理方面不切实际。所以,有必要将捕获的低阶增强为高阶。在一份专利申请中,苹果就介绍了如何生成增强的Ambisonics格式。
在一个实施例中,所述系统以FOA格式接收音频内容,所述FOA格式可以包括第一组音频信号。通过根据虚拟扬声器阵列的布局,对第一组音频信号进行空间渲染,从而产生空间渲染的音频信号。
系统通过对所述第一组音频信号中的至少一个执行参数分析来确定一个或多个滤波器,并使用所述滤波器对所述空间渲染的音频信号中的至少一个进行滤波。基于空间渲染的音频信号,系统以Higher-Order Ambisonics(HOA)格式产生第二组音频信号。
所以,由于原始接收音频内容的增强,系统能够在捕获时具有低通道计数,但在渲染时具有高分辨率。
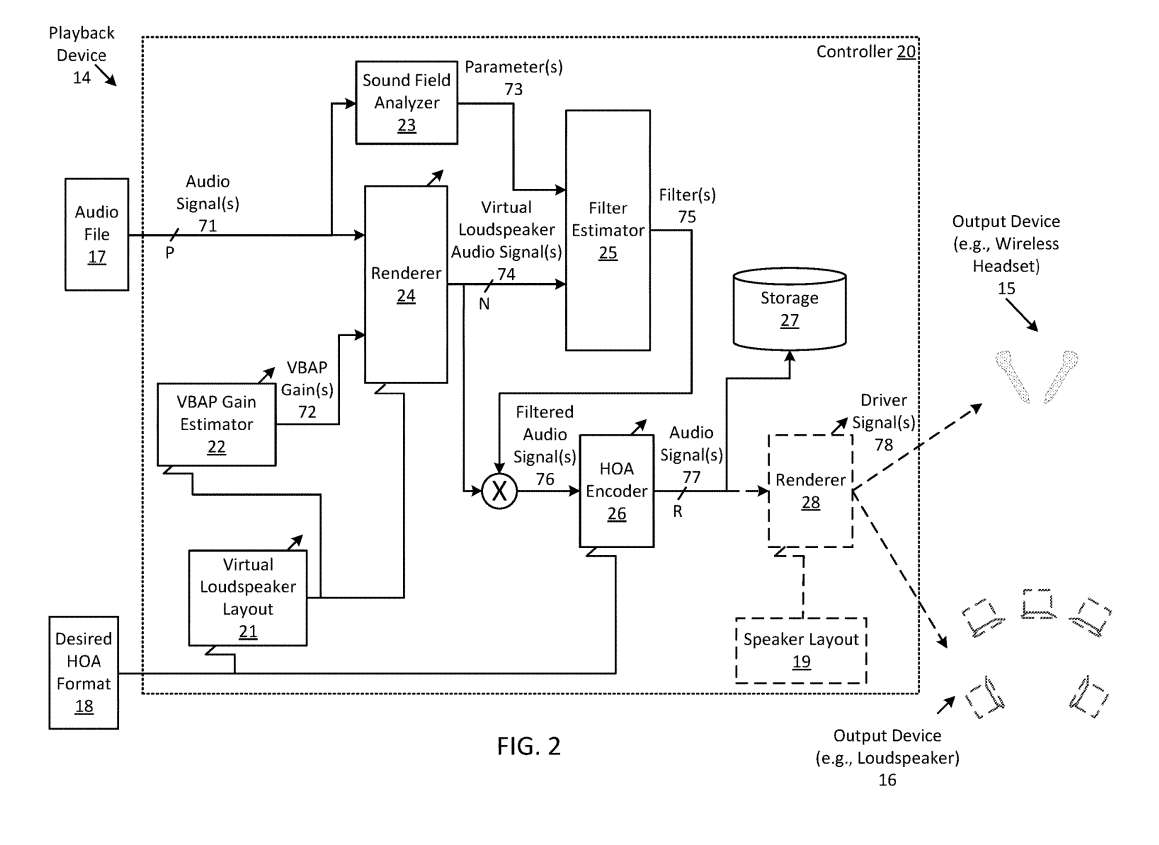
图2是系统播放设备的框图。播放设备14包括音频文件17、所需的HOA格式18和控制器20。控制器20具有若干操作块,用于执行音频空间处理以产生音频内容的增强立体声格式。如图所示,控制器包括虚拟扬声器布局21、增益估计器22、声场分析仪23、(空间音频)渲染器24、滤波器估计器25、HOA编码器26、存储器27、(可选)渲染器28和所需扬声器布局19(可选)。
控制器20可以配置为接收音频文件17,其中包括音频内容的“P”音频信号71。音频内容可以采用球形音频格式,例如FOA音频格式。在一个方面,控制器可以基于用户输入接收音频文件。例如,用户可以请求由控制器20执行的媒体软件应用程序以流式传输音频内容。
在这种情况下,控制器20可以通过网络13作为FOA表示接收音频内容。或者,控制器20可以从存储器检索音频文件17。可以将控制器20配置为确定将所接收的音频信号作为所述音频信号的所期望的HOA格式18向上混合的HOA格式。在一个方面,控制器20可以从存储器检索所需的HOA格式18,和/或可以根据用户输入接收所需的格式。
可以将虚拟扬声器布局21配置为基于HOA格式18确定虚拟扬声器阵列的布局。增益估计器22可以配置为确定一个或多个矢量基幅度平移(VBAP)增益,用于基于所需的HOA格式18在空间渲染音频信号71的音频内容。
具体地,估计器可以基于由所述布局21确定的虚拟扬声器阵列的布局确定一个或多个VBAP增益。VBAP可以使用三个扬声器的三角测量来产生3D声音,作为扬声器区域内的虚拟声源。为了产生3D声音,VBAP产生一个增益向量(例如,三个增益,每个扬声器一个),然后可以将其作为扬声器增益应用于一个或多个输入音频信号。
可以将渲染器24配置为接收音频文件17和VBAP增益72的音频内容(音频信号71),并根据虚拟扬声器阵列的布局(来自布局21)对信号71进行空间渲染,从而产生若干虚拟扬声器音频信号74作为空间渲染的音频信号。
渲染器24可以使用VBAP增益空间渲染(例如,线性渲染)音频信号71。在一个方面,渲染器可以通过对至少一定的音频信号71施加(VBAP增益72来线性渲染音频信号,以产生虚拟扬声器信号74。在一个方面,渲染器可以产生N个虚拟音频信号74,为由布局21确定的虚拟扬声器阵列的每个虚拟扬声器至少一个信号(基于所需的HOA格式18)。
一方面,为了在空间渲染音频信号71的声场,渲染器可以在声场内确定一个或多个虚拟声源,其中虚拟声源可以与虚拟扬声器阵列的一个或多个虚拟扬声器相关联。然后,选择与虚拟扬声器阵列的虚拟扬声器相关联的VBAP增益72,并可将其应用于与虚拟扬声器相关联的一个或多个音频信号。在一个方面,渲染器可以使用任何空间渲染方法将音频信号71渲染到与所需的HOA格式相关联的虚拟扬声器阵列。
因此,可以将控制器20配置为确定来自所需HOA格式18的增益72,以匹配相应的虚拟扬声器设置。虚拟扬声器的虚拟位置可以基于增益推导,一旦确定了增益,渲染器可以通过将一个或多个增益分配给虚拟扬声器来确定虚拟扬声器之间的虚拟声源。
如上所述,控制器20可以配置为将音频内容转换为虚拟扬声器音频信号74,。一方面,如果空间渲染的音频信号被用来驱动阵列的扬声器,由其产生的声音非常相关,所以不太理想。在这种情况下,为了改善声音,可以将控制器配置为通过执行参数分析以产生滤波器来增强音频内容,以便在将信号重新编码为更高阶之前将其应用于至少一定的虚拟信号。因此,所述控制器可配置为将原格式混合成具有更高空间分辨率的更高阶。
声场分析器23可以配置为接收音频信号71并对所述信号执行声场分析,以确定(产生)与所述音频文件17的音频内容的声场相关联的一个或多个(空间)参数73。一方面,分析可以在时频域进行。在这种情况下,所述控制器可配置成将所述音频信号71变换为所述时频信号,所述音频信号71可在时域内。
时频信号可包括音频信号相对于时间(或作为时间的函数)的频率分量。所述分析器23可以确定声场的至少一定时频信号的参数。例如,分析器23可以基于至少一定时频信号的声学分析,确定与声场的一个或多个声源相关联的DoA。所述分析器23可确定可指示声场的一个或多个声音的空间特性的其他参数。
滤波器估计器25可以配置为接收由分析器23产生的参数73和音频信号74中的一个或多个(可从时域变换为时频域),并且可以配置为基于参数73和/或至少一定音频信号74估计(或确定)一个或多个自适应滤波器75。
滤波器75可包括锐化滤波器,其可提供音频内容的空间渲染的空间增强。例如,当应用于一个或多个虚拟扬声器音频信号74时,锐化滤波器可增强一个或多个信号的方向分量。在这种情况下,滤波器可以增强声场内一个或多个声源的声音。
在一方面,滤波器75可以是非线性和/或线性滤波器。锐化滤波器可以是任何类型的音频滤波器,如高通滤波器、低通滤波器、带通滤波器等。
控制器20可以配置为通过将所述滤波器75应用所述虚拟扬声器音频信号74中的一个或多个来产生滤波的音频信号76。在一个方面,控制器可以使用一个或多个滤波器滤波信号74,以便改进(增强)音频内容的空间分辨率。
在一个方面,HOA编码器26可以在时频域对信号76进行编码。在这种情况下,控制器可以对音频信号77施加逆时频变换,将信号变换为时域。在另一方面,控制器可以在HOA编码器26将音频内容重新编码为所需的HOA格式18之前将信号76转换为时域。控制器20可以配置成将所需的HOA格式的音频信号77存储在存储器27中。
在一方面,控制器可以任选地通过一个或多个输出设备在空间渲染编码的HOA数据。例如,渲染器28可以以编码的HOA格式接收音频信号77,并且可以通过基于(根据)诸如输出设备15的扬声器布局19对音频信号77中进行空间渲染来产生一个或多个渲染(或驱动)信号78。
在一个方面,扬声器布局19可以包括一个或多个输出设备的扬声器的排列指示。例如,对于包括五个扬声器的输出设备16,扬声器布局19可以指示扬声器的数量和/或扬声器相对于彼此的放置。控制器20可配置为确定可通信耦合到播放设备14的输出设备的扬声器布局19。
在一个方面,渲染器28可以对所述音频信号77中的一个或多个执行非参数空间音频渲染,以产生一个或多个驱动信号。在头戴式头显的情况下,渲染器28可以产生两个驱动信号。在一个方面,渲染器28可以在空间渲染的信号应用一个或多个空间滤波器,例如头相关传递函数HRTF。
渲染器可以对双声道音频信号77执行线性空间渲染以产生两个渲染信号(左信号和右信号),并且可以应用HRTF来产生一个或多个双声道音频信号作为一个或多个输出音频信号78。在另一方面,渲染器28可以执行任何类型的空间渲染技术,以基于扬声器布局19从音频信号77产生空间渲染的音频信号78。
在一个方面,渲染器28可以基于来自系统10的一个或多个感器的头追踪数据调整渲染。例如,所述输出设备15可包括一个或多个头追踪传感器,所述头追踪传感器可监测用户的头部运动,并可将运动提供给所述渲染器28,而所述渲染器28可相应地调整所述空间渲染。
图3和5示出用于执行用于从另一音频格式产生增强音频格式的一个或多个音频信号处理操作。
转到图3,处理30开始于控制器20以FOA格式接收音频内容,所述格式包括第一组音频信号。例如,控制器20可以接收包含FOA音频内容的音频信号71音频文件17。控制器20通过根据虚拟扬声器阵列的布局对音频信号71进行空间渲染来产生若干空间渲染的音频信号。
例如,控制器可以为接收到的FOA数据确定所需的HOA格式,并且可以根据所需格式确定布局。控制器可以确定一个或多个VBAP增益72,并且可以将所述增益应用于所接收的音频内容以产生所述空间渲染的音频信号74。
控制器20通过对所接收的音频信号71中的至少一个执行参数分析来确定一个或多个滤波器75。所述控制器20使用所述一个或多个滤波器滤波所述空间渲染的音频信号中的至少一个。控制器产生第二组音频信号,其中所述音频信号是基于空间渲染的音频信号的HOA格式。
控制器20可将滤波器75应用于空间渲染的音频信号74以产生滤波后的音频信号76,其中控制器可将音频信号编码为HOA格式。
在另一方面,播放设备可以在空间渲染音频内容,以供作为播放设备一部分的一个或多个扬声器播放。在这种情况下,控制器20可以确定播放设备的扬声器布局,并且可以使用驱动信号来驱动其扬声器进行播放。
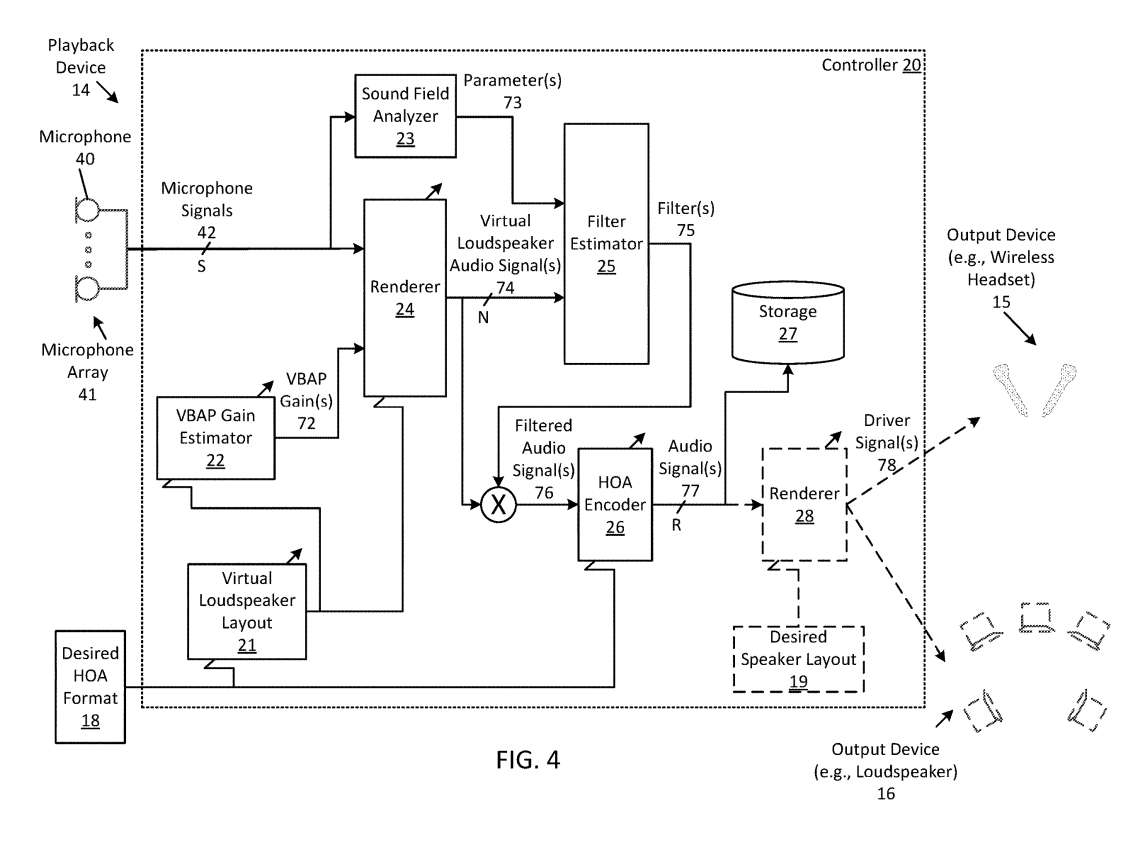
图4是从一个或多个麦克风信号产生增强型格式的系统框图。所述框图与图2的框图类似,只是所述播放设备14包括具有一个或多个麦克风40的麦克风阵列41。在这种情况下,控制器20可以接收S个麦克风信号42,每个麦克风信号包括由麦克风阵列41的相应麦克风40捕获的环境声音。在这种情况下,麦克风信号42可以包括声场,声场具有所述环境的一个或多个声音。
在一个方面,控制器20可以执行发明描述的一个或多个操作来从麦克风阵列41捕获的S个麦克风信号42中的一个或多个产生增强的格式。
在这种情况下,渲染器24可以接收由估计器基于期望的HOA格式产生的麦克风信号42和VBAP增益72,并且可以根据虚拟扬声器的布局并使用VBAP增益将麦克风信号渲染为多个虚拟扬声器音频信号74。
特别是,声场分析仪23可以通过对一个或多个麦克风信号42执行参数分析来确定与麦克风捕获的环境声音相关的一个或多个参数73。渲染器24可以通过将麦克风信号空间渲染到虚拟扬声器阵列来产生空间渲染的音频信号,并且可以通过基于一个或多个参数滤波空间渲染的信号来产生滤波信号76。HOA编码器26可以将滤波后的信号编码为本文所述的HOA信号。
所以,由HOA编码器26产生的HOA格式可以是来自麦克风信号42的上混,由此产生的R HOA信号77可以包括比S麦克风信号更多的音频信号。
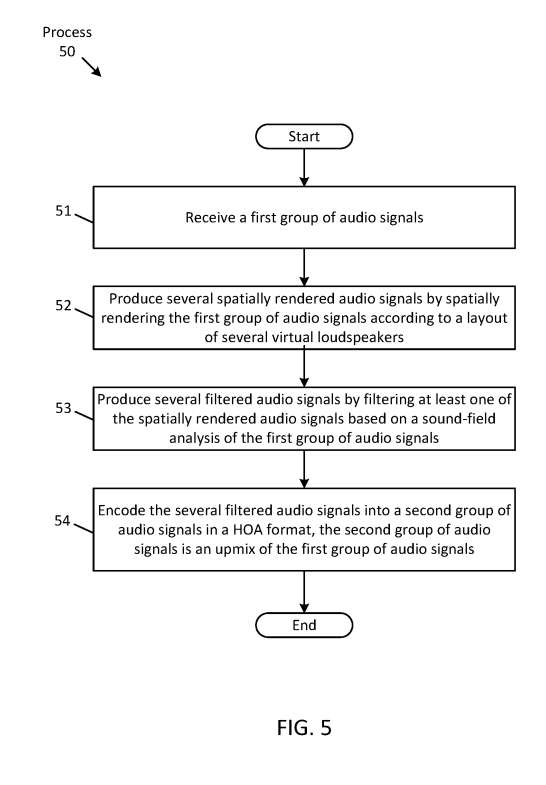
图5是由系统10执行的过程50,以根据另一方面产生音频内容的增强格式。处理50开始于控制器20接收第一组音频信号。例如,音频信号可以是双声信号,其可以是音频文件的一部分和/或可以包括一个或多个包括环境环境的音频内容的麦克风信号。
一方面,双声信号可以包括任何类型的音频内容,例如XR环境的声音。
控制器20通过根据若干虚拟扬声器的布局对第一组音频信号进行空间渲染来产生若干空间渲染的音频信号。
控制器可以基于所接收信号将被编码成的所需HOA格式在空间上渲染所述信号。控制器20通过基于对第一组音频信号的声场分析滤波空间渲染的音频信号中的至少一个来产生几个滤波的音频信号。
控制器可以产生基于声场分析的滤波器,以便锐化或增强在所接收的音频信号中捕获的声场的空间分辨率。控制器20以HOA格式将若干滤波后的音频信号编码为第二组音频信号,其中第二组音频信号是第一组音频信号的上混。
相关专利:Apple Patent | Method and system for producing an augmented ambisonic format
名为“Method and system for producing an augmented ambisonic format”的苹果专利申请最初在2023年9月提交,并在日前由美国专利商标局公布。