
(
映维网Nweon
2024年12月02日
)当在AR/VR/MR环境中放置Avatar时,需要确定Avatar的大小。大小不合适的Avatar可能会造成尴尬的
社交
场景,或者在与Avatar交互时造成用户疲劳。
例如,如果一个Avatar相对太大或太小,为了与Avatar进行眼神交流,用户可能需要将头或身体维持在一个不舒服的位置。另外,大小不合适的Avatar可能会传达错误的社交信息,例如Avatar与用户之间隐含的优越感(当Avatar比用户大时)或自卑感(例如当Avatar比用户小时)。
在一份专利申请中,
Magic Leap
提出可以在生成Avatar时根据上下文信息自动确定Avatar的适当尺寸,包括用户的位置,Avatar在其他用户环境中的渲染位置,用户和Avatar之间的相对高度差,渲染环境中对象的存在等等。可穿戴系统可以根据上下文信息自动缩放Avatar,增加或最大限度地增加直接的目光接触,从而促进Avatar与用户的交流。
在一个实施例中,可穿戴系统可以根据与用户环境、用户动作、用户意图等相关的上下文信息提取用户交互的意图。可穿戴系统可以根据Avatar所处的环境,将用户交互的世界运动映射到Avatar的动作,并将用户交互的局部动作直接映射到Avatar。世界运动的映射可以包括调整Avatar的一个或多个特征,例如眼睛注视等,以与Avatar呈现的物理环境相兼容(而不是简单地以直接一对一的方式映射特征)。
例如,当爱丽丝走向椅子并坐在椅子上时,可穿戴系统可以通过从鲍勃所处环境的世界地图中获取信息并将爱丽丝呈现为坐在椅子,从而自动找到鲍勃所处环境中的椅子(如果没有椅子,则可以找到另一个可坐表面)。
作为另一个示例,可穿戴系统可以确定爱丽丝打算感兴趣对象进行交互。可穿戴系统可以自动重新定位爱丽丝的Avatar,并与鲍勃环境中感兴趣对象进行交互。其中,感兴趣的对象的位置可以与爱丽丝环境中的位置不一样。例如,如果对虚拟书进行直接的一对一映射会导致它在鲍勃环境中呈现在桌子里面或桌子下面,则鲍勃的可穿戴系统会将虚拟书呈现为放在桌子上面,这将为鲍勃提供爱丽丝和虚拟书更自然的交互。
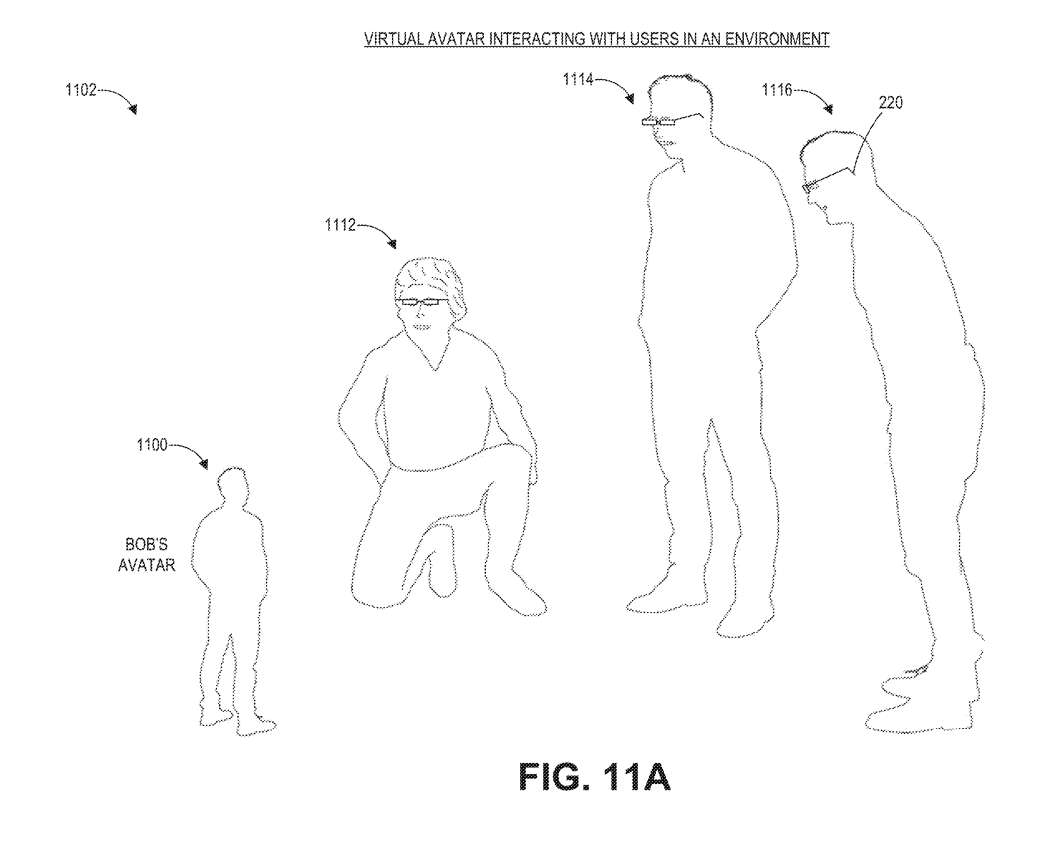
图11A示出一个示例场景1102,其中三个用户1112、1114和1116在远程呈现会话期间与Avatar1100交互。然而,鲍勃的Avatar1100与三个用户1112、1114和1116相比相对较小,这可能会导致尴尬的交互,因为人们通常在保持目光接触和接近眼睛高度的情况下彼此交流最舒服。
所以,由于Avatar和三个用户之间的视线不同,三个用户可能需要维持不舒服的姿势才能与Avatar1100保持眼神交流。为了减少用户因不合适大小Avatar所造成的身体压力,可穿戴系统可以根据上下文信息(例如其他用户眼睛的高度)自动缩放Avatar。
这种调整可以通过增加或最大化Avatar与其他人之间的直接目光接触的方式来实现,从而促进Avatar与人类的交流。
另外,将用户的特征与Avatar的特征进行一对一的映射可能会产生问题,因为它可能会产生不自然的用户交互,或者传达错误的信息或用户意图。
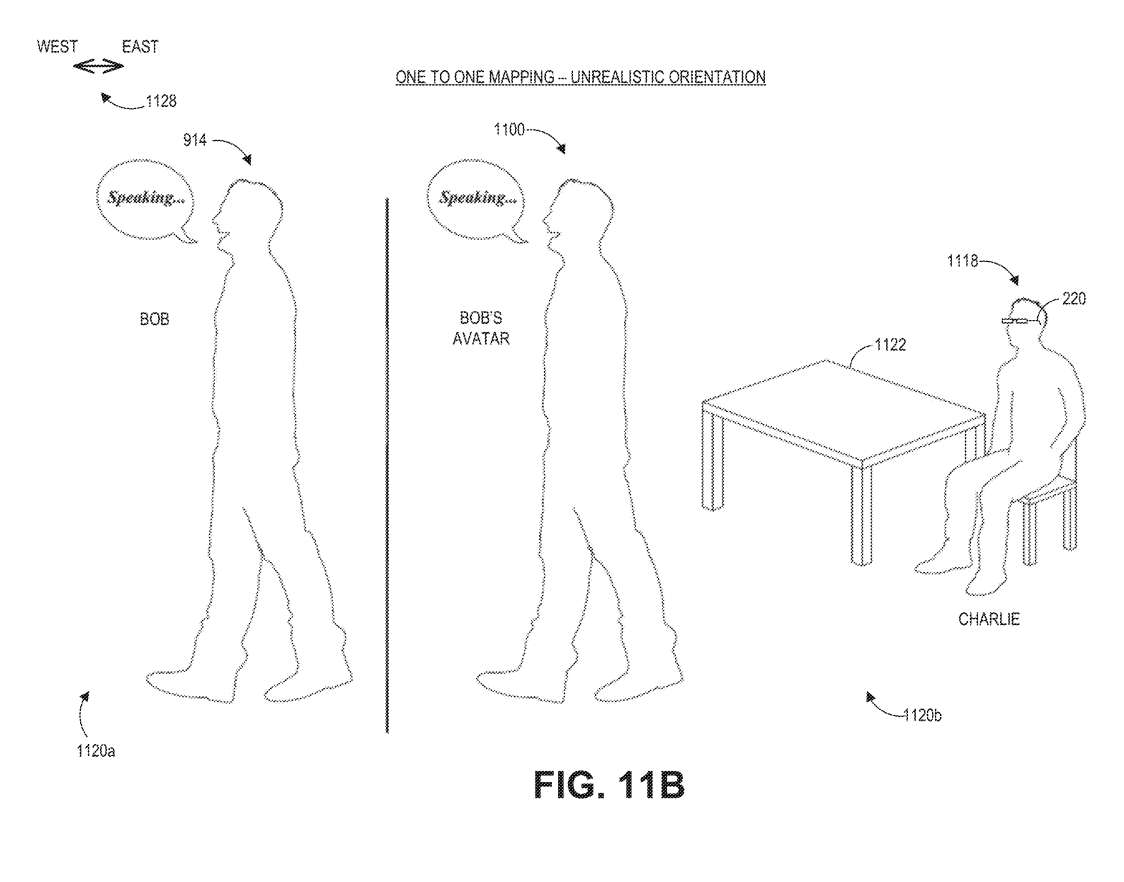
图11B说明了鲍勃在远程呈现会议期间与查理交谈的场景。图中的场景包括1120a和1120b两个环境。环境1120a是鲍勃所在的环境。环境1120b是查理1118所在的地方,它包括一张物理桌子1122,查理坐在桌子1122旁边的椅子上。查理可以感知鲍勃的Avatar1100。在环境1120a中,鲍勃朝西(如坐标1128所示)。
为了动画鲍勃的Avatar1100,在图11B中,鲍勃的914个特征一一映射到鲍勃的Avatar1100。然而,这种映射有问题,因为它没有考虑到查理的环境,并且它与Avatar1100产生了不自然或不愉快的用户交互体验。
例如,鲍勃的Avatar比查理1118高,因为查理1118坐在椅子上,查理1118可能需要伸直脖子才能与鲍勃的Avatar1100保持眼神交流。另一个例子是,鲍勃的Avatar1100面朝西方,因为鲍勃面朝西方。然而,查理1118在鲍勃的Avatar1100的东面。
所以,查理1118感知到鲍勃Avatar的背部,而无法观察到鲍勃Avatar1100反射出的面部表情。鲍勃Avatar1100相对于查理的方向可能传达不准确的社交信息,例如即便鲍勃打算与查理进行友好的交谈,但这会传达出“鲍勃不想与查理接触”或“鲍勃对查理很生气”。
对于这一点,可穿戴系统可以配置为基于与显示Avatar的环境相关的上下文信息来呈现Avatar,或用于传达用户的意图(而不是直接的、一对一的映射)。例如,可穿戴系统可以分析上下文信息和鲍勃的行为,以确定鲍勃的行为意图。可穿戴系统200可以根据鲍勃的动作和鲍勃的Avatar所处环境的上下文信息,调整鲍勃的Avatar的特征,从容反映鲍勃的意图。
参照图11B,可穿戴系统200可以将Avatar1100转向查理1118,而不是将其朝西呈现,因为鲍勃打算与查理1118进行友好的交谈,而这种交谈通常为面对面。但如果鲍勃对查理1118生气,例如根据麦克风检测到鲍勃讲话的语气、内容、音量或鲍勃的面部表情来确定,可穿戴系统200可以保持鲍勃的914方向,以令鲍勃背离查理1118。
尽管用户可以手动缩放Avatar,但这种手动控制可能需要更多的时间来完成,并且需要用户对Avatar进行精细的调整,从而导致用户肌肉疲劳。
对于这一点,Magic Leap提出可穿戴系统可以基于有关Avatar在环境中的呈现位置和用户在环境中的位置或眼高的上下文信息自动缩放Avatar。可穿戴系统可以根据上下文因素计算Avatar的大小,例如Avatar的渲染位置,用户的位置,用户的高度,用户与Avatar之间的相对位置,用户站立或坐着的表面的高度等等。
可穿戴系统同时可以响应上下文信息的变化而动态缩放Avatar。
例如,在生成Avatar之前,可穿戴系统可以确定用户的头高以及眼高,并计算从Avatar的基础表面到用户眼睛高度的距离。这个距离可以用来缩放Avatar,使其最终的头部和视线与用户的高度相同。可穿戴系统可以识别环境表面,并根据表面或用户与Avatar表面之间的相对高度差来调整Avatar的高度。
在一个实施例中,当用户在环境中移动(或Avatar移动)时,可穿戴系统可以持续追踪用户的头部姿势和环境表面,并根据环境因素动态调整Avatar的大小。自动缩放Avatar的技术可以在最大限度地减少颈部疲劳的同时进行直接的目光接触,以促进用户与Avatar的交流,并最大限度地减少用户在将Avatar放置在用户本地环境中时需要进行的手动调整量,从而允许用户进行眼睛对眼睛的交流,创造一个舒适的双向交互。
在一个实施例中,可穿戴系统可以允许用户关闭自动的Avatar缩放。例如,如果用户在远程呈现会话期间频繁地站起来和坐下,用户可能不希望Avatar相应地重新调整大小,这可能会导致不舒服的交互,因为人类在对话期间不会动态地改变大小。
可穿戴系统可以配置为在不同模式的Avatar缩放选项之间切换。例如,可穿戴系统可以提供三种缩放选项:
基于上下文信息的自动调整
手动控制
1:1缩放。
可穿戴系统可以根据上下文信息自动调整默认值。用户可以根据用户输入将默认选项切换到其他选项。在其他实施例中,可穿戴系统可以平滑地在大小变化之间进行插值,以便在短时间内将Avatar呈现为平滑地改变大小,而不是突然改变大小。
图12A和12B说明了缩放Avatar的两个场景。图12A中的场景1200a显示了一个不正确缩放的Avatar,而图12B中的场景1200b显示了一个与用户保持大致相同眼高的缩放Avatar。
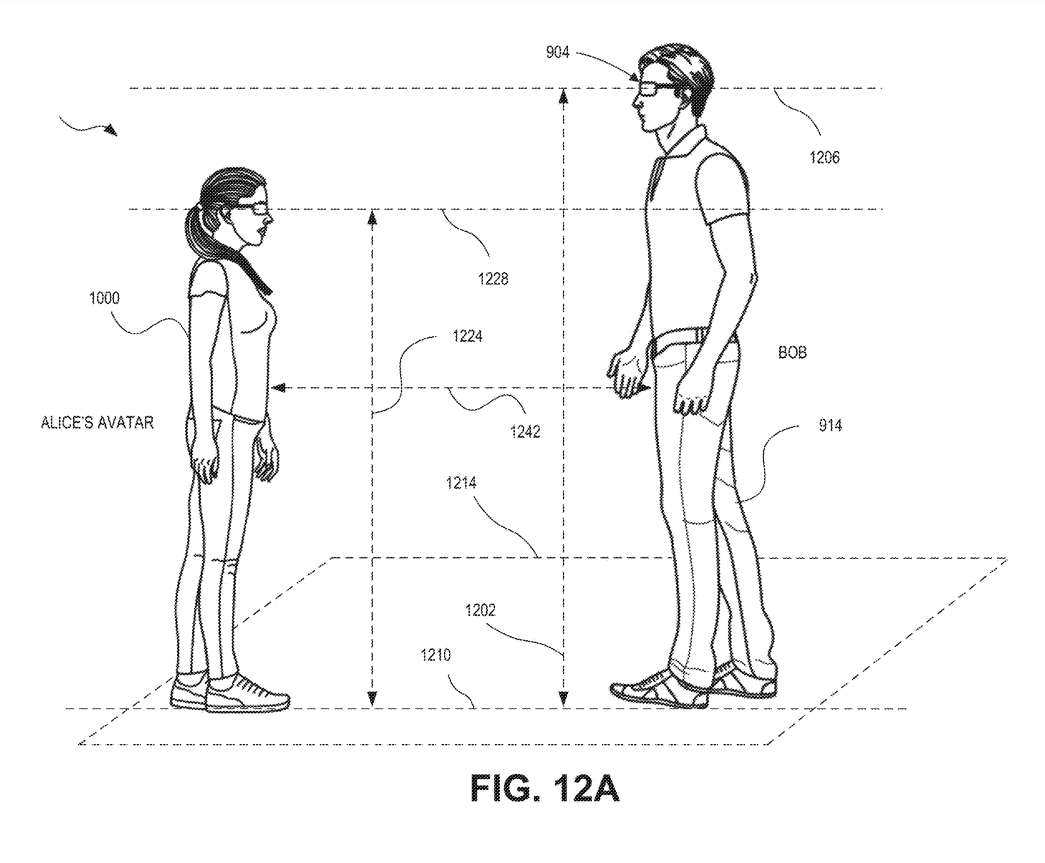
在图12A中,爱丽丝的Avatar1000太小,以至于鲍勃在与爱丽丝的Avatar1000交互时需要向下看。爱丽丝的Avatar100和鲍勃的高度可以从公共地位置线1210测量。
图12A同时示出鲍勃的914眼位(如用户眼位线1206所示)和Avatar的眼位(如Avatar眼位线1228所示)。Avatar视线线1228和用户视线线1206分别表示为平行于地面位置线1210并与虚拟Avatar1000和用户914的眼睛相交。用户视线线1206和Avatar视线线1228中的每一个可以对应于各自的平面(未示出),其包含相应的视线线并且平行于地平面1214。用户视线1206和Avatar视线1228中的一个或两个可以平行于地平面1214。
为了确定所述Avatar的大小,所述可穿戴系统可以计算用户914的高度和所述Avatar1000的高度1224。所述Avatar的高度和所述用户的高度可以从所述Avatar和所述用户各自的视线垂直于所站地面1214来测量。
如图12A所示,可以在Avatar视线线1228和地面位置线1210之间确定Avatar视线高度1224。类似地,可以在用户视线线1206和地面位置线1210之间确定用户视线高度1202。
在一个实施例中,可以将系统配置为确定用户与虚拟Avatar的渲染位置之间的距离1242。距离1242可用于在用户914更舒适的位置显示虚拟Avatar1000。例如,可穿戴系统可以在Avatar相对远离用户的情况下增加Avatar的尺寸,以便用户可以更好地看到Avatar。
在图12A所示的示例中,Avatar1000的大小不合适,因为用户视线线1206与Avatar视线线1228不共线对齐。这表明Avatar1000太小。
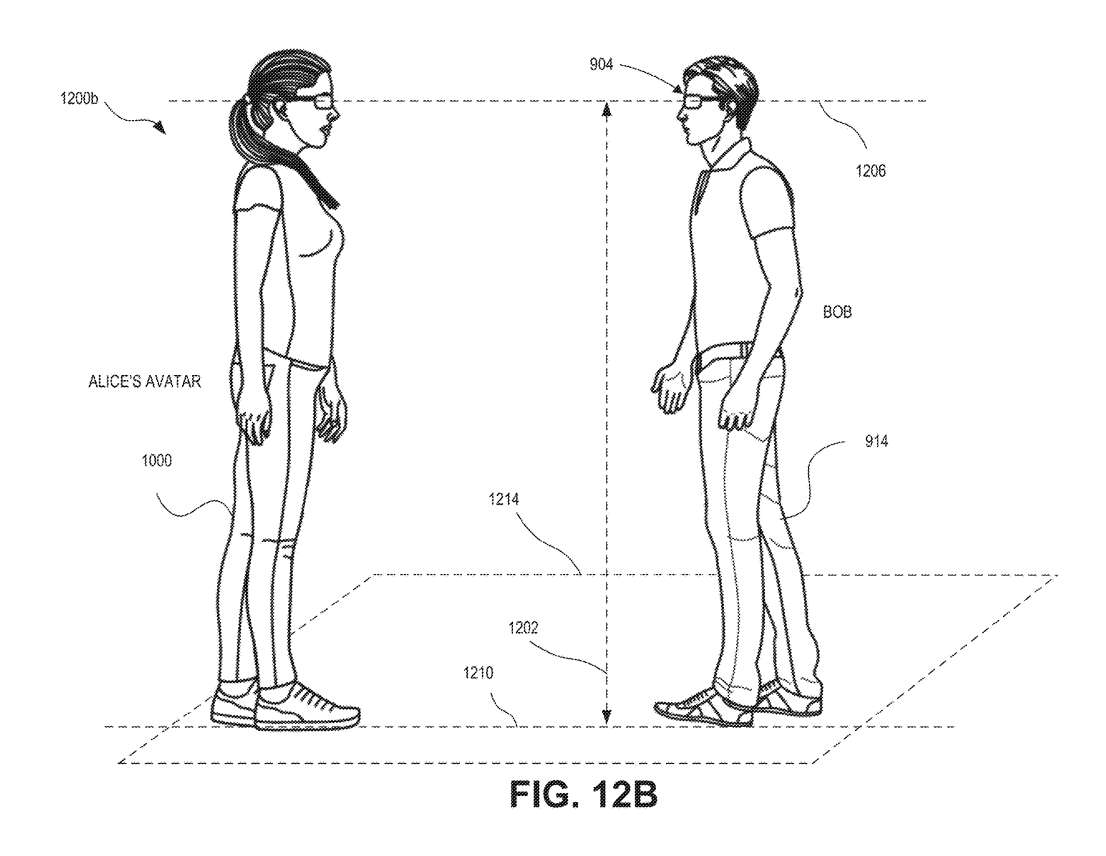
图12B显示的虚拟Avatar1000的大小相对于鲍勃恰当地渲染。在本例中,虚拟Avatar是根据用户的眼高进行缩放。缩放虚拟Avatar1000可包括匹配Avatar眼睛高度1224和用户眼睛高度1202。
如发明所述,可穿戴系统可以配置为自动识别上下文因素,以计算虚拟Avatar的目标高度并生成虚拟Avatar或实时动态调整虚拟Avatar的大小。

图13示出基于上下文因素自动缩放Avatar的流程图。
可穿戴系统可包括一个或多个设备传感器1674。从设备传感器1674获取的数据可用于确定用户的环境,以及确定用户相对于环境的位置。
摄像头校准1688可用于确定世界帧中的头部定位1682。世界帧中的这种头部定位1682可以输入到Avatar自动缩放器中,并且可以用作确定用户头部位置1604的输入,以自动缩放Avatar。
所述设备传感器可包括一个或多个深度传感器,获取的深度数据可以用来创建一个环境点云1678,它可以包含用户环境的3D数学表示。可穿戴系统可以基于环境点云1678识别主要水平面,如桌面、地面、墙壁、椅子表面、平台等。
可穿戴系统可以将点云转换为网格环境。通过深度摄像头标定1688,可穿戴系统可以将点云1678转换为世界参考帧中的网格化环境。深度摄像头校准可以包括如何将从深度摄像头获得的点云的位置与可穿戴设备参考框架或环境参考帧中的位置相关联的信息。
在1684,可穿戴系统可以在世界参考系中近似平面环境,参考系可以包括来自网格的平面提取。平面提取可以将三角形分组成方向相似的区域。然后,可以对网格化区域进行进一步处理,以提取代表环境中平面区域的纯平面区域。
在1686,可穿戴系统可以执行进一步处理,从环境中提取主要水平面。可穿戴系统可以配置为基于从1684识别区域的表面方向、大小或形状来确定主要水平面。
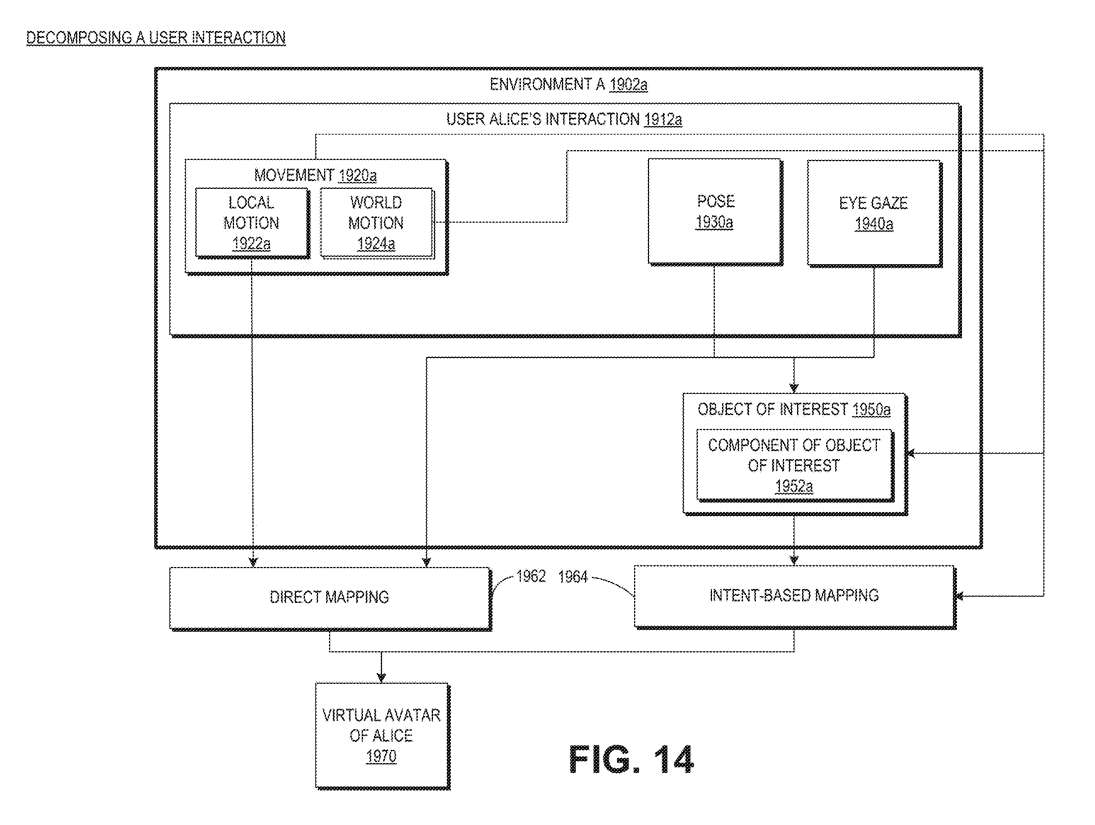
图14描述了用于分解用户交互的系统的示例。运动1920a可分解为局部运动1922a和/或世界运动1924a。局部运动1922a可以包括相对于固定体参照系的运动,并且可以不与环境1902a交互。世界运动1924a可以包括涉及与环境1902a交互的运动。这样的世界运动1924a可以用世界坐标系来描述。例如,爱丽丝可能在她的环境中跑步。手臂运动可以认为是局部运动1922a,而腿部运动可以认为是世界运动1924a。
可穿戴系统可以使用直接映射1962将交互1912a的局部晕动映射到虚拟Avatar1970。例如,可穿戴系统可以使用直接映射1962,将局部运动1922a、姿势1930a或眼睛注视1940a映射到Avatar1970的动作中。
可穿戴系统可以使用基于意图的映射来映射交互的世界组件。基于意图的映射1964的结果是,Avatar1970的动作达到了与爱丽丝执行的相应交互1912a相同的目的,但Avatar1970的动作可以与爱丽丝的动作不完全相同。
通过将用户交互分解为世界组件和本地组件,系统可以通过实现更快的处理、减少存储要求和改善延迟。
相关专利
:
Magic Leap Patent | Avatar customization for optimal gaze discrimination
名为“Avatar customization for optimal gaze discrimination”的Magic Leap专利申请最初在2024年7月提交,并在日前由美国专利商标局公布。