
(
映维网Nweon
2024年10月22日
)3D重建是指从多视图数据中再现3D场景,并对于诸如AR/VR和电子商务等计算机视觉应用至关重要。然而,从图像数据中重建和渲染大规模室内场景具有挑战性。
在一份专利申请中,
Adobe
就提出了一种快速大规模辐射场重建方法。发明提出的场景重建系统将场景建模为神经体积辐射场,并可以再现忠实的场景外观,产生逼真的新颖视图合成结果。具体而言,实施例可以在大规模场景执行快速辐射场重建(这里所说的“大规模”是指全尺寸的室内场景,例如ScanNet数据集中的场景)。
为了在具有挑战性的场景中实现快速的辐射场重建,发明使用了一种全新的神经框架,通过循环神经模块从输入图像序列中逐步重建大型稀疏辐射场。与之前需要对每个场景进行优化的神经技术不同,Adobe提出的场景重建系统具有通用性,可以跨场景进行预训练,并且能够通过直接网络推理有效地重建大规模的辐射场。
在一个实施例中,给定具有已知camera姿势的RGB图像的输入序列,将辐射场重构为稀疏神经体。输入序列的处理与经典的TSDF处理相似,后者从逐视图几何(深度)开始,融合跨关键帧的逐视图重建,以获得全局稀疏的TSDF体积。尽管这个工作流的经典版本广泛用于重建大规模场景,但它只用于几何重建,不能产生照片般的效果。相反,实施例使用神经模块将辐射场重建为稀疏体素,以用于逼真的渲染。
在一个实施例中,为每个输入关键帧重建局部辐射场。例如,世界空间成本体积是由邻近关键帧的未投影2D图像特征构建。稀疏三维卷积可以应用于成本体积来重建代表局部辐射场的稀疏神经体素。
一旦估计,这个域就可以用来渲染真实的图像局部,但只有局部帧看到的部分场景内容。为了使其支持大场景,循环神经融合模块用于顺序融合多个局部领域跨帧。融合模块循环地将新估计的局部场作为输入,并学习合并局部体素,逐步重建整个场景的全局辐射场。
更新包括添加新的体素和/或更新现有的体素。整个模型从端到端进行训练,学习从任意数量的输入图像中重建具有任意场景尺度的辐射场。这允许直接的网络输出来呈现高质量的图像,不需要特定场景的训练。
另外,可以将特定场景的微调应用于神经领域,以优化预测的体素特征,从而获得更好的渲染质量。这种微调可以在数分钟内完成,并实现渲染质量等于或优于之前需要数小时或数天特定场景培训的技术。
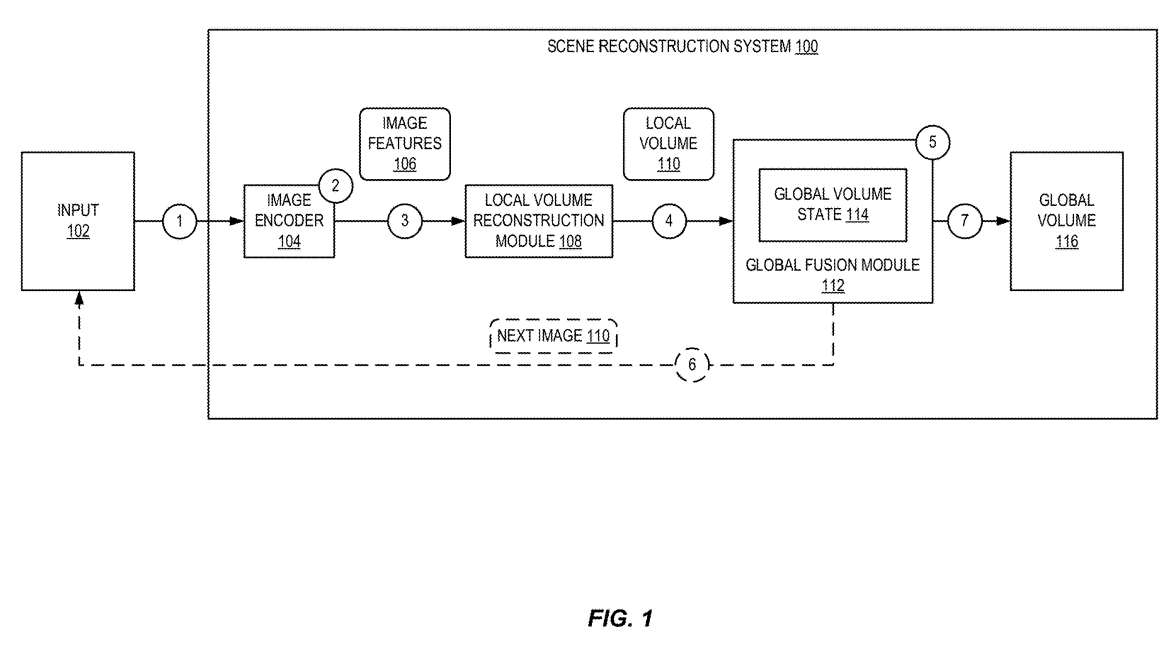
图1示出场景重建过程的示意图。场景重建可由场景重建系统100执行。场景重建系统100可以实现为独立应用程序、基于云或基于服务的应用程序等。
给定图像的输入序列,场景重建系统100重建一个辐射场建模整个场景逼真的渲染。如图1所示,场景重构系统100接收输入102。输入102可以包括视频或任何其他图像序列。例如,单目摄像机可捕获重建场景的连续视频。
如数字1所示,来自输入102的图像传递到图像编码器104。图像编码器104可以包括从输入图像提取2D特征的卷积神经网络或其他机器学习模型。特别是,神经网络可以包括相互连接的数字神经元的模型,模型通信并学习近似复杂函数,同时基于提供给模型的多个输入生成输出。
例如,神经网络包括一个或多个机器学习算法。换句话说,神经网络是一种实现深度学习技术的算法,即利用一组算法试图对数据中的高级抽象进行建模的机器学习。
如数字2所示,图像编码器104处理所接收的图像并输出相应的图像特征106。在一个实施例中,来自输入102的所有图像可由图像编码器104处理以创建相应的图像特征106。或者,仅图像的子集由图像编码器104处理。
如数字3所示,图像特征由本地体积重构模块108接收。局部体重建模块108包括一个机器学习模型,如3D CNN,模型基于正在处理的当前图像和一个或多个相邻视图的图像特征回归局部体积110。
如数字4所示,将本地体积提供给融合模块112。融合模块112可以包括维持状态的机器学习模型,例如循环神经网络。融合模块112接收本地体积110并将其添加到编号为5的全局体积状态114。
融合模块112是一种全局神经体积融合网络,其增量地将局部特征体积融合为全局体积。在一个实施例中,融合模块包括宿命循环单元和3D CNN的组合,允许融合模块112学习循环地融合每帧局部重建并输出高质量的全局辐射场。
例如在数字6,如果在输入102中保留额外的图像,则场景重建系统100处理下一个图像,并将产生的新局部体积融合到全局体积。通过增量地执行这种融合,可以细化特征,并在接收到新数据时填充漏洞。
在数字7,处理完所有图像后,全局体积状态114输出为全局卷116。全局体积是一个稀疏的神经体,表示一个辐射场。然后可以使用全局体积来合成场景的新视图。
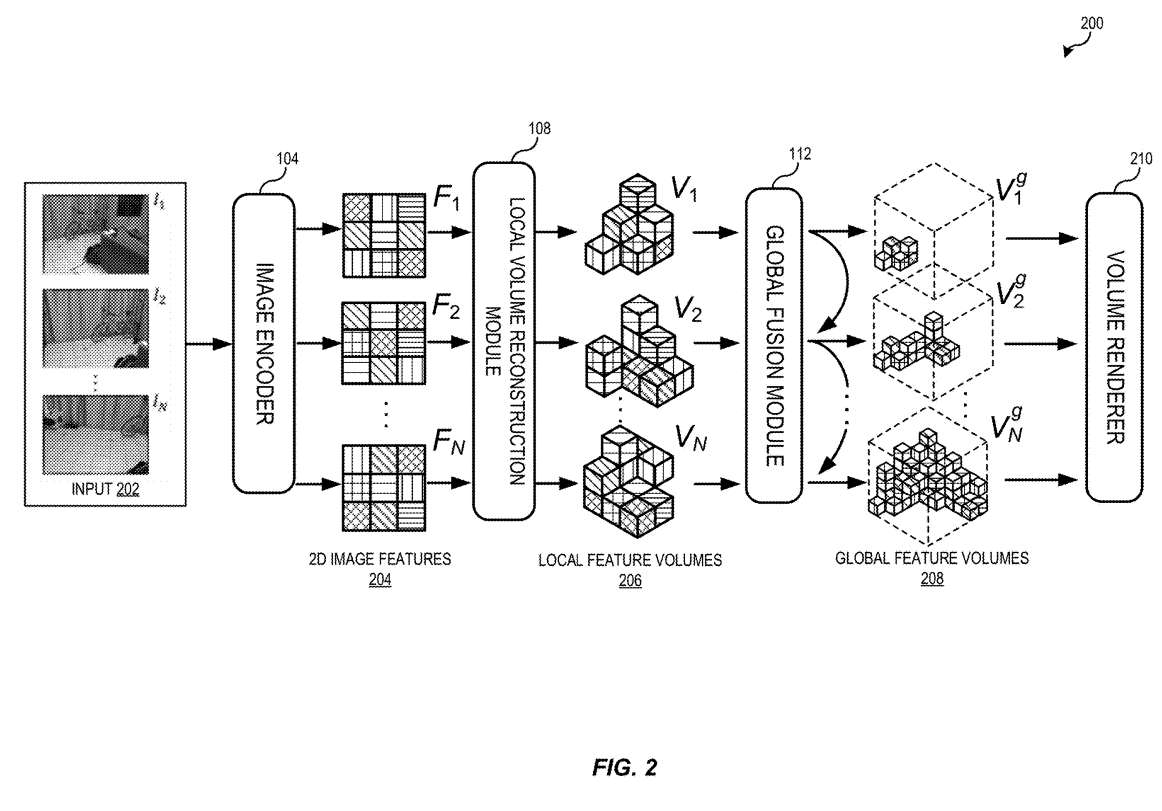
图2示出从输入图像序列重建用于场景的神经体的框架200。框架200使用深度神经网络对每个输入帧t回归局部神经体积,使用其图像It和来自相邻视图的K−1图像。
通常,给定单目视频,相邻视图对应于时间相邻帧。使用多个附近的图像进行每帧重建,使网络能够利用多视图对应来恢复比单独使用单个图像更好的场景几何形状。
为了使每帧的局部重建在场景中很好地泛化,实施例使用深度多视图立体视觉MVS技术。实施例提取2D图像特征,从特征中构建成本体积,并从成本体积中回归神经特征体积。然而,与MVSNeRF和其他MVS技术在视图的视角坐标中构建视锥体体不同,场景重建系统在规范的世界坐标框架中构建体积,使其与最终的全局体输出Vg对齐,从而促进增量融合过程。
在一个实施例中,图像编码器104是深度2D卷积神经网络,其为每个输入图像提取2D图像特征204。网络将输入图像It映射到2D特征映射Ft中,对每个视图的场景内容进行编码。将二维图像特征204提供给局部体积重构模块108。
在一个实施例中,确定覆盖世界坐标框架中所有K个相邻视点的截锥体的边界框。这个边界框包含规范空间中的一组体素。边界体与世界框架轴向对齐,其中的每个体素可以对不同数量的相邻视图可见。
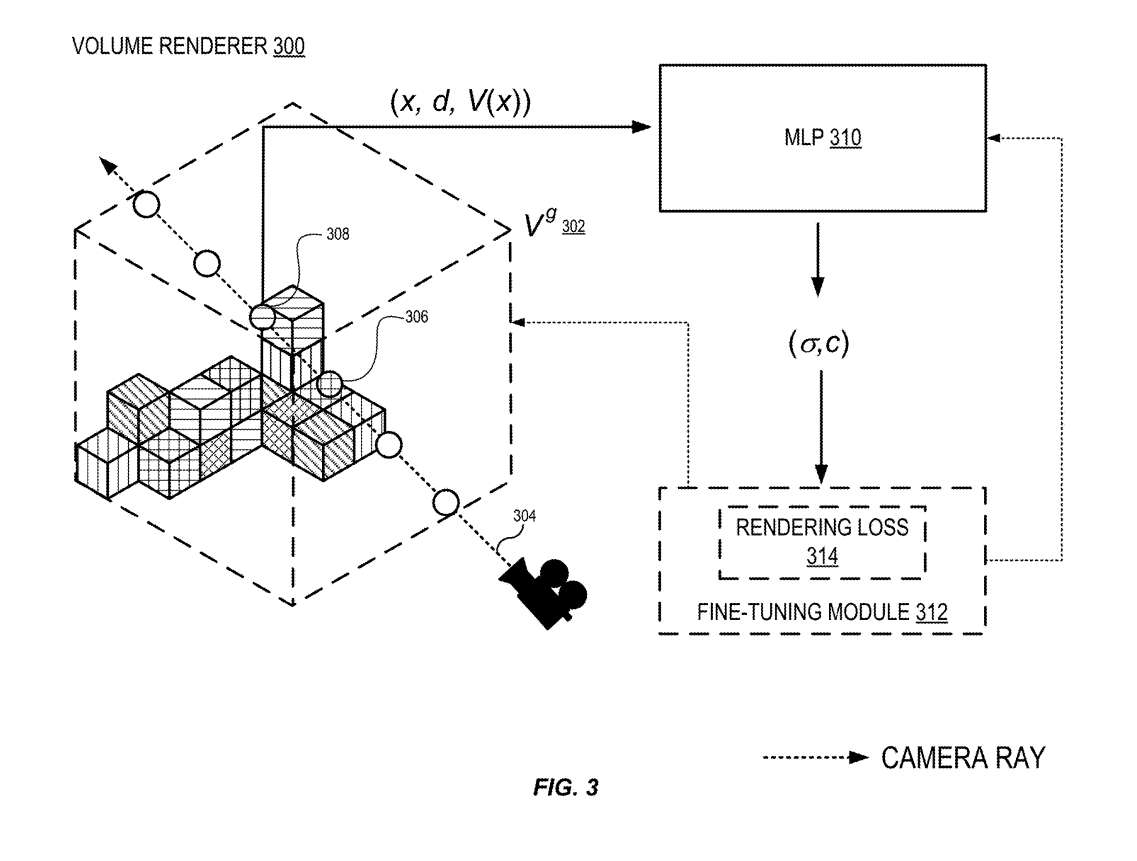
图3示出使用体渲染器呈现新视图的过程。
如图3所示,体积渲染器300可以使用全局体积Vg 302从任意观看方向和观看位置渲染场景视图。例如,用户、应用或其他实体可以选择一个观看方向d。
射线304然后沿着所述观看方向从观看位置穿过全局体积Vg 302。体渲染器确定光线与体素相交的位置,例如在306和308处,并将信息提供给MLP 310。MLP回归点的体积密度σ和与视图相关的辐射度c。利用体密度和视相关辐射,通过体渲染技术合成新的视点。
如前所述,直接推理用于实时或接近实时地生成新的视点。然而,微调可以用于渲染场景的更真实的视图。为了对估计的辐射场进行微调,微调模块312优化稀疏体积重建Vg和MLP解码器310中每个场景的每体素神经特征,从而获得更好的渲染结果。
由于最初的重建提供了最先进或接近最先进的渲染结果,所以少于25 k次迭代的短时间优化通常可以产生非常高的质量,而这只需要不到一个小时的时间。比NeRF和其他纯逐场景优化方法所需的优化时间要少得多。
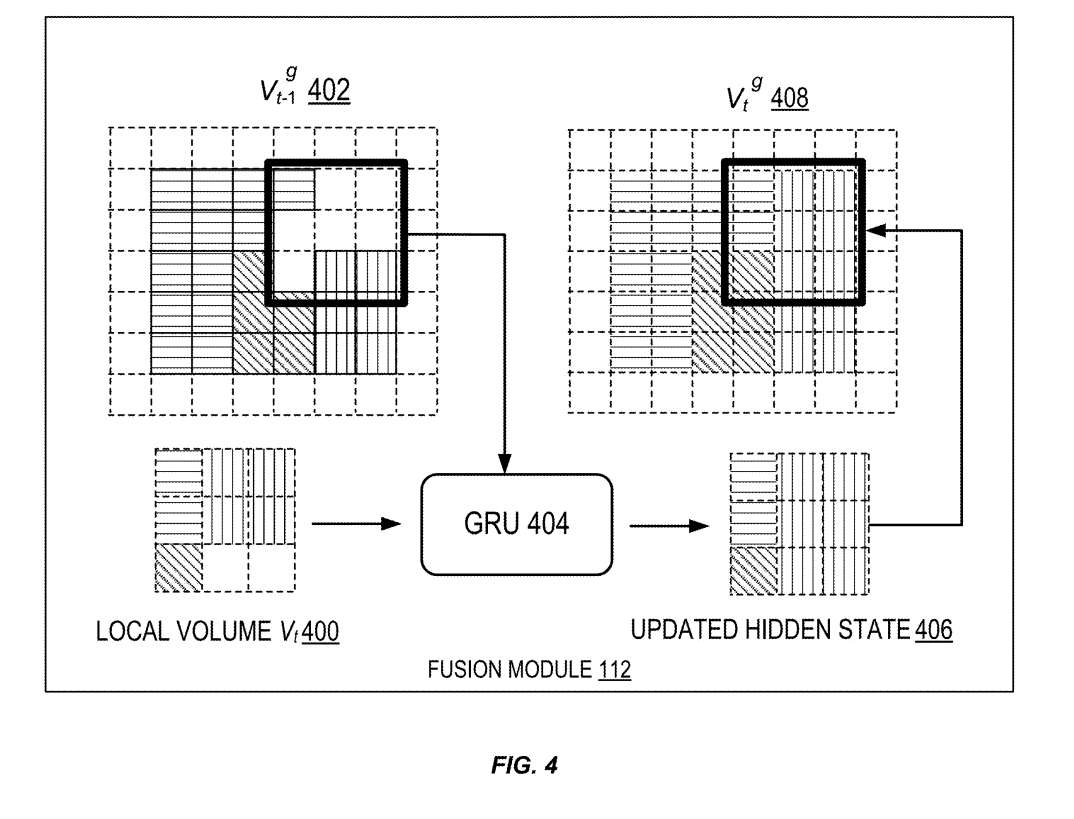
在图4的示例中,当处理新帧时,创建新的本地体积Vt 400。这个新的本地体积400与先前的全局体积Vt-1g 402一起由GRU 404处理。
如图所示,先前的全局体积Vt-1g 402存在一定的缺失区域。GRU基于新的本地体积400和先前的全局体积Vt-1g 402自适应地更新其隐藏状态,以创建更新的隐藏状态406。
如上所述,局部体积和全局体积是在同一个坐标空间中构造。相应地,基于更新后的隐藏状态406更新全局体积Vtg 408。这包括用新的体素填充洞,扩展网格以包含额外的体素,和/或细化现有体素的特征。
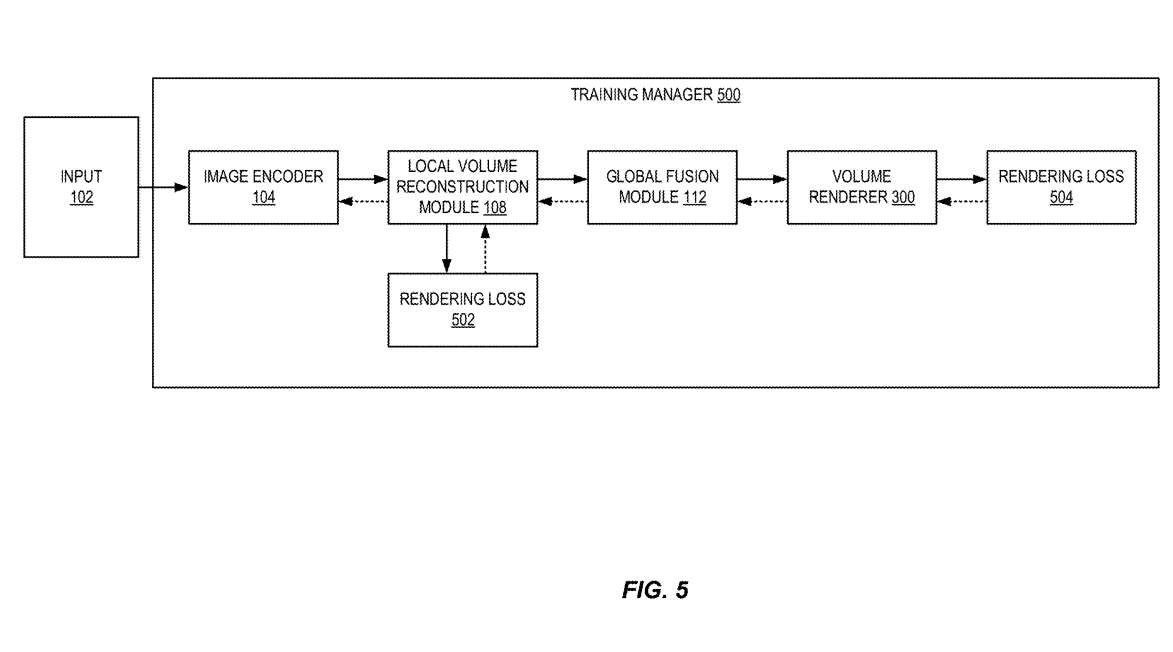
图5示出训练场景重建系统的示例。先前的辐射场技术需要逐场景优化。这意味着在合成新的视图之前,需要大量的时间(例如12小时以上)来训练特定场景的模型。
但与先前的技术不同,Adobe的发明使用数据集跨场景训练模型,并且训练后的模型可以通过直接推理来估计字段。
经过训练后,整个网络能够从直接网络推断中输出高质量的辐射场,并产生逼真的渲染结果。另外,重建的辐射场作为一个稀疏的神经体可以很容易地优化(微调)每个场景,从而进一步提高渲染质量。
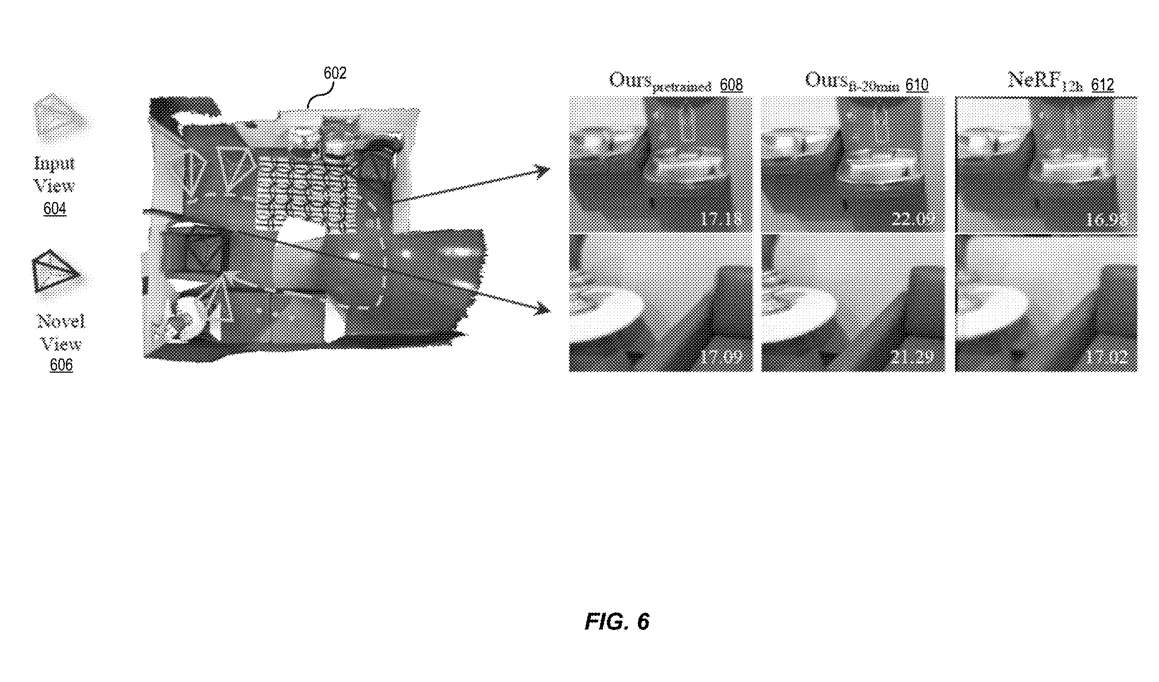
图6示出快速重建大规模场景的体积辐射场的比较600。
如图6所示,摄像头可以捕获场景602的连续单目视频。然后按发明所述处理帧或从中采样的图像。这就产生了一个全局辐射场,可以用来合成场景的新视图606。
新视图重建的示例显示为由场景重建系统的直接推理608。如图所示,直接推理608产生的结果与NeRF 612实现类似,而微调场景重建系统610产生的重建结果明显更逼真。
因此,实施例可以通过直接推理产生与最先进模型相当的结果,而所需的资源和时间显著减少。另外,加上一个短暂的微调期,场景重建系统可以产生更逼真的结果。
图7示出场景重建系统。如图所示,场景重建系统700可以包括用户界面管理器702、图像编码器704、本地体积重建模块706、全局体积融合模块708、体积渲染器710、神经网络管理器712、培训管理器714和存储管理器716。存储管理器716包括输入图像718和重构的全局体积724。
用户界面管理器702允许用户请求场景重建系统700从输入图像生成重建的全局体积720。同样,用户界面管理器702可以使用户能够指定观看方向,并使场景重建系统从指定的观看方向呈现新的视图。
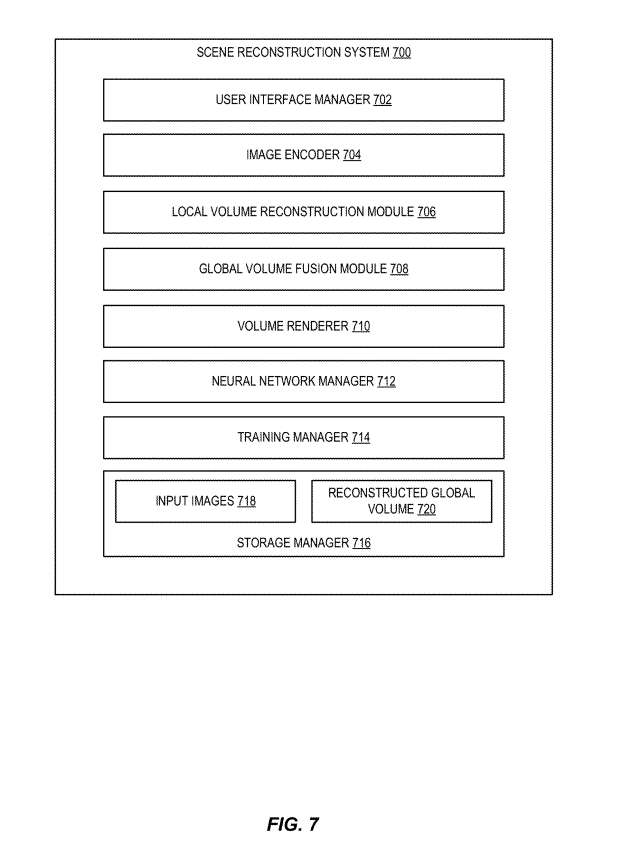
如图7所示,场景重构系统700包括图像编码器704。图像编码器704可以是处理输入图像并输出相应图像特征的机器学习模型。
场景重构系统700包括局部体重构模块706。局部体积重建模块706负责从图像编码器704提取的图像特征中回归局部体积。
场景重建系统700包括全局体积融合模块708。全局融合模块708接收来自本地体积重构模块706的本地体积,并将其融合到全局体积。如前所述,本地体积和全局体积是在相同的规范空间中创建。全局融合模块708可以使用诸如GRU的递归神经网络来实现,并且将全局体积保持为其隐藏状态。一旦所有帧都处理完毕,最后的隐藏状态是重建的全局体积,并可以用来合成场景的新视图。
场景重建系统700包括体积渲染器710。体积渲染器710负责使用全局体积Vg从任意观看方向渲染场景的新视图。
场景重建系统700同时包括神经网络管理器7712。神经网络管理器712可以托管多个神经网络或其他机器学习模型,例如图像编码器704或局部体积重建模块706、全局体积融合模块708或体积渲染器710的神经网络。
场景重建系统700进一步包括训练管理器714。训练管理器714可以教授、引导、调整和/或训练一个或多个神经网络。特别地,训练管理器714可以基于多个训练数据训练神经网络。
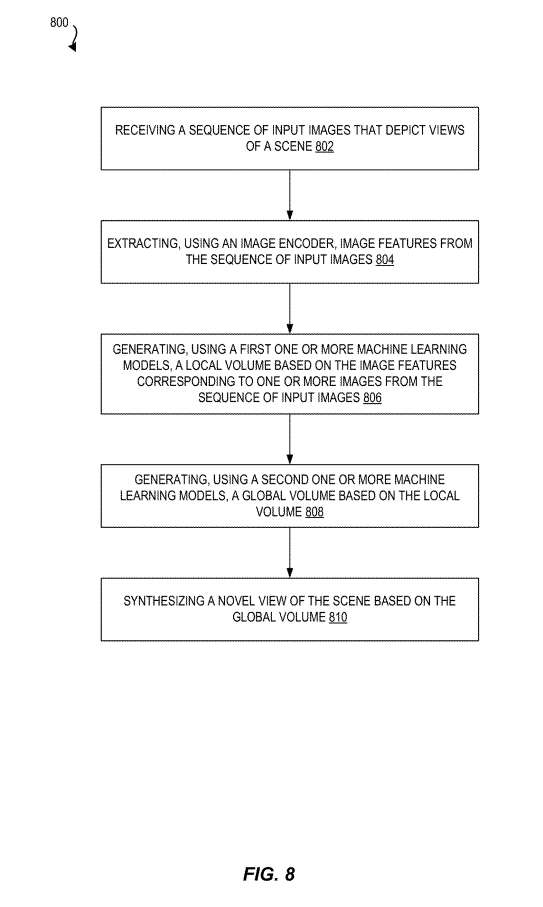
图8示出快速大规模辐射场重建方法的流程图800。
在802,方法800包括接收描述场景视图的输入图像序列。
在804,方法800包括使用图像编码器从输入图像序列提取图像特征的行为8。
在806,方法800包括使用第一种或多种机器学习模型基于与输入图像序列中的一种或多种图像相对应的图像特征生成局部体积。
在808,方法800包括使用第二个或多个机器学习模型生成基于局部体积的全局体积。
在810,方法800包括基于全局体积合成场景的新视图。
相关专利
:
Adobe Patent | Fast large-scale radiance field reconstruction
名为”Fast large-scale radiance field reconstruction“的Adobe专利申请最初在2023年3月提交,并在日前由美国专利商标局公布。