
(
映维网Nweon
2024年09月23日
)游戏通常包含与相关视频数据一起播放的音频。游戏原声通常是在开发游戏时生成,它包含一个或多个音频文件并与电子游戏的游戏数据一起提供。例如,原声带可由多个音轨组成,而音轨以预先定义的顺序一个接一个地播放。但在特定游戏中,播放曲目的顺序取决于游戏内事件。
有的电子游戏采用算法音乐生成,即基于游戏内事件,从声音样本的集合中实时构建配乐。然而,尽管这种方法在原声中提供了一定程度的个性化,但原声的个性化程度受到所提供的声音样本数量的限制。所以,提供具有更大程度个性化的配乐将是有利的。
在一个专利申请中,
索尼
就介绍了一种为游戏生成乐谱的方法,并可用于VR头显设备。
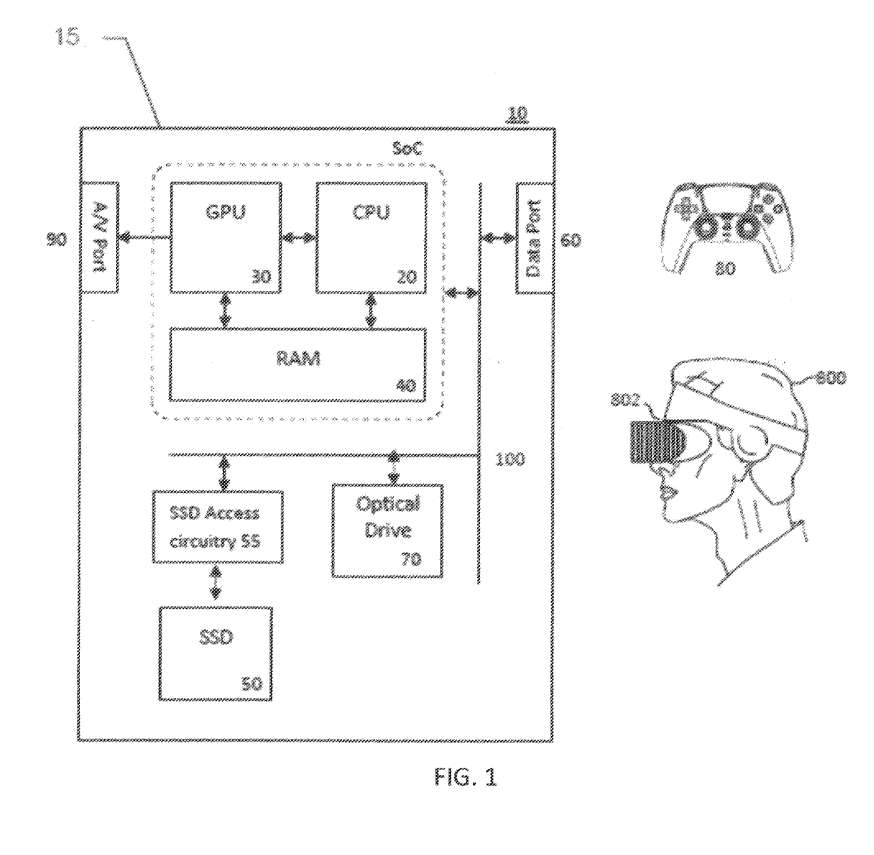
图1显示了娱乐系统10的示例,包括娱乐设备15(例如PS5)、显示设备(例如头显802)和一个或多个手持控制器80。
娱乐设备15包括中央处理器20。来自娱乐设备的音频/视频输出通常通过一个或多个A/V端口90,或通过一个或多个有线或无线数据端口60提供。例如,娱乐设备的处理电路20、30可以基于任何接收电路接收到的游戏资产生成游戏内容,并通过A/V端口90或有线或无线数据端口60输出游戏内容。
所述处理电路20、30同时可以通过所述有线或无线数据端口60的AV端口90为所述游戏输出乐谱或配乐。或者,娱乐设备可以将游戏asset直接传输到显示设备,显示设备的处理电路可以生成游戏内容。
头戴式显示器可以用来提供更好的沉浸感,特别是在虚拟现实游戏中。
头显802或控制器80中的一个或两个可以包括一个或多个传感器,并用于检测用户800的生理状况,例如,一个或多个传感器可以检测用户的温度、心率、眼球运动、坐姿、眨眼、运动或任何其他生理状况中的一个或多个,并向娱乐设备输出表示检测到的生理状况的信号。
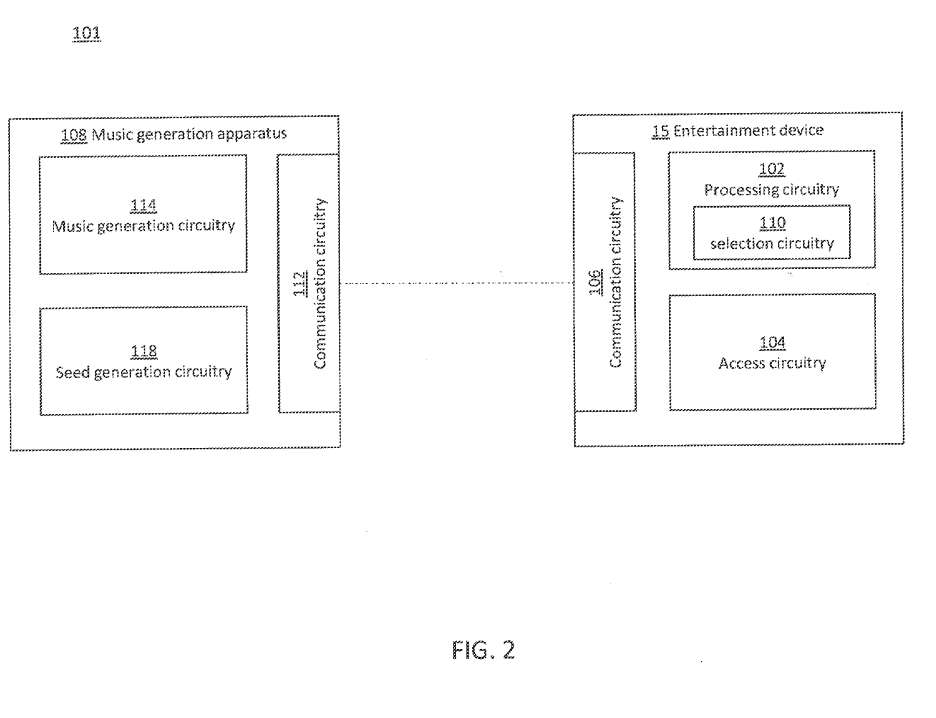
图2示出了包括娱乐设备15和音乐产生装置的系统101。
娱乐设备15是包括处理电路,其用于处理依赖于游戏数据和与玩游戏的用户相关的动作和/或条件的游戏的游戏状态。娱乐设备同时包括选择电路,其用于在处理游戏期间依赖于与用户相关的动作和/或条件进行选择。
所述娱乐设备15使用所述通信电路106与音乐产生设备108进行通信。所述音乐生成设备108可以是本地设备,在这种情况下,所述娱乐设备的通信电路106可以通过有线连接或短距离/本地无线连接与所述音乐生成设备106通信。
或者,音乐生成设备108可以在远程服务器内提供,远程服务器可通过互联网对娱乐设备进行访问,例如,音乐生成设备108可以作为云服务的一部分提供,并且可以对多个远程娱乐设备进行访问。在另一示例中,音乐产生设备108可与娱乐设备15集成,在这种情况下,通信电路106可由总线100提供。
所述音乐生成设备108设置为为正在由所述娱乐设备15处理的游戏提供个性化乐谱。因此,所述音乐生成设备是用于为游戏生成乐谱的音乐生成设备示例。
更具体地说,所述音乐生成设备可以生成乐谱本身,或所述乐谱的某种表示形式。因此,所述音乐生成设备108产生并输出指示乐谱的信息。
所述音乐生成设备108包括用于与所述娱乐设备15通信的通信电路112,所述娱乐设备15的通信电路106与所述音乐生成设备108之间的通信包括由所述娱乐设备15发送的请求,要求所述音乐生成设备为游戏生成乐谱。
通信同时包括一个或多个关键字,并通过选择电路110选择。因此,音乐产生设备108的通信电路112配置为接收为游戏生成乐谱的请求,并接收娱乐设备在处理游戏期间输出的一个或多个关键字,其中一个或多个关键字指示与玩游戏的用户相关的动作和/或条件,和/或部分或全部游戏状态本身。输入信号可以包括与用户动作相关的信息和与用户相关的可选生理数据。
音乐生成设备108同时包括音乐生成电路114,其响应于开始生成指示乐谱的信息的请求,并且响应于接收一个或多个关键字中的每一个,以依赖于关键字更新指示乐谱信息的生成。
特别地,音乐生成电路114响应于接收生成乐谱以根据请求中提供的信息开始生成指示乐谱的信息的请求的通信电路112。然后,指示乐谱的信息在其生成时,通过音乐生成设备的通信电路112输出到娱乐设备15。
指示乐谱的信息最初是基于请求中提供的信息生成。例如,请求可以任选地识别正在播放的游戏,并且可以类似地任选地识别有关用户的用户配置文件信息。
这允许针对特定游戏和单个用户对乐谱进行个性化。然而,当通信电路112接收到一个或多个关键词时,所述音乐生成电路114通过更新其基于所述关键词的指示乐谱的信息的生成来进行响应。这为游戏、用户以及用户与游戏的交互和反应提供了个性化的乐谱。
注意,娱乐设备15和音乐产生设备108之间的通信可以不直接从一个设备流向另一个设备,而是可以通过一个或多个中间设备传输。
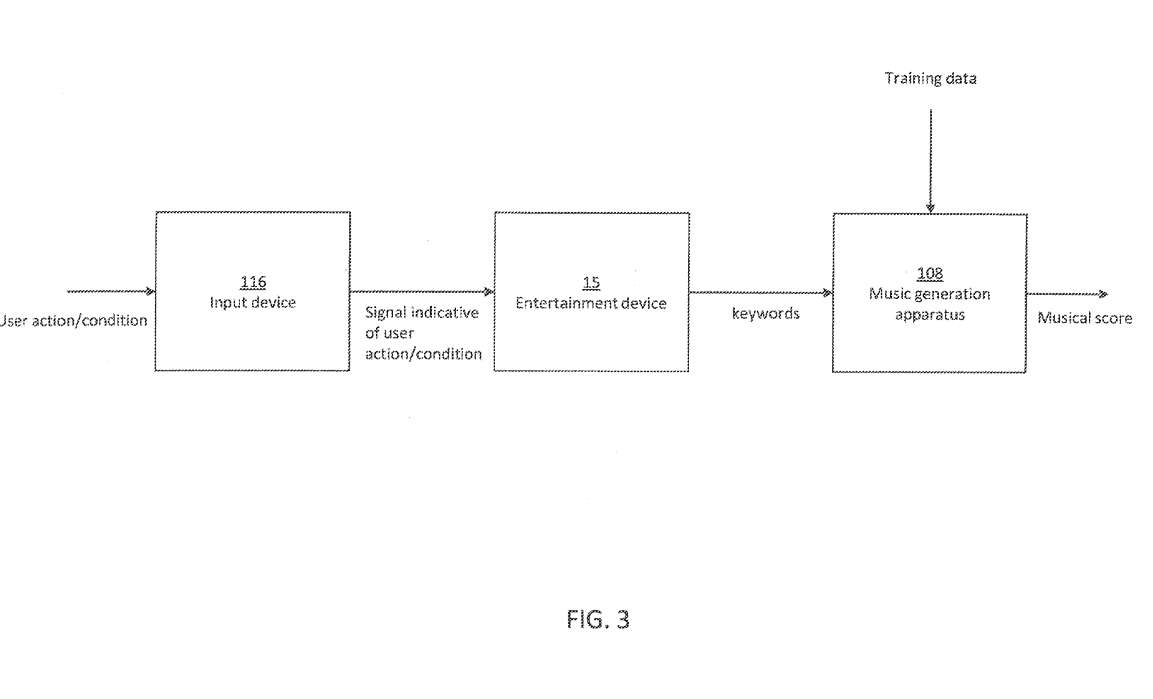
音乐产生设备108产生指示乐谱的信息的过程如图3所示。在本例中,音乐生成设备108实现了机器学习或人工智能程序。
为原则上,经过适当训练的人工智能可以在生成乐谱指示信息时提供无限的个性化。然而,为这个目的实现AI非常重要,特别是在定义AI的输入数据时。
为AI定义输入数据以确保生成的乐谱能够反映用户与游戏的交互和反应,需要的不仅仅是将输入设备116的输入数据馈送到AI,因为所述信息只识别有关用户的信息,而不是用户与游戏的交互方式。
例如,如果用户按下控制器上的特定按钮,这一事实本身并不能确定他们是如何与游戏交互的——他们与游戏的交互同时是由游戏本身的状态、用户按下按钮之前或之后立即采取的其他行动、用户所处的游戏阶段等等所定义。为AI定义反映所有这些因素的输入数据可能具有挑战性。
除了提供来自输入设备116的输入数据外,一种选择可能是在游戏进行时向AI提供有关游戏的信息。然而,通信如此大量的数据将需要电路提供大带宽。另外,训练AI从这些数据中生成指示乐谱的信息将会非常复杂,因为对于单一的用户和游戏组合,存在大量不同的用户输入、用户条件和游戏事件组合,更不用说跨越一系列不同的用户和不同的游戏。这样的人工智能同时需要强大的处理能力。
索尼提出的解决方案不需要在娱乐设备15和音乐生成设备108之间传输如此大量的数据,并且训练AI会更简单。
特别地,娱乐设备15响应指示从为单个游戏定义的关键字池中选择的一个或多个用户动作、条件或游戏状态的信号,其中一个或多个关键字表示用户与游戏的交互或对游戏的反应,或游戏状态。
关键词池可以针对特定游戏进行定义或细化,因此可以对其进行安排,以反映特定游戏提供的特定主题和场景。所以,当娱乐设备将这些关键词提供给音乐生成设备108时,AI可以使用相关术语来生成乐谱。
因此,发明提出了一种允许AI/ML算法根据用户的输入/反应和/或用户如何选择游戏进程来生成高度个性化乐谱的机制。
AI可以使用训练数据进行训练,包括乐谱/电子游戏音轨的部分,以及选择的相应关键字,以反映如何使用音轨的部分来表示用户与游戏的各种交和/或游戏状态。另外,AI在使用过程中继续接受训练。例如,用户有时可能需要回答,他们是否觉得生成的乐谱符合他们的情绪和/或他们与游戏的交互。用户对问题的回答反馈给人工智能以改进其模型。
现在回到图2。值得注意的是,经过充分训练的人工智能依然是一个典型的确定性过程。所以对于相同的关键字提示,它可能生成相同的音乐输出,这确实可能是一个理想的属性。然而,这对于用户来说可能会变得重复,并且/或者如果开发者想要为类似的状态制作听起来相似但不相同的音乐,则将关键字与游戏状态关联起来的过程就会变得更加繁琐。
在AI输入中添加seed值与添加噪点类似,对于相同的关键词,不同的种子将致使AI产生不同的输出。但由于这个过程依然是确定性的,添加相同的seed和关键词将再次产生相同的输出。
因此,每个seed的动作都改变了提示音,因此改变了音乐输出。这可以用于简化关键字词汇表,或者将关键字与用户或游戏状态进行标记/关联,从而为相同的关键字创造差异。
类似地,特定的seed可与游戏名称或游戏开发者相关联,并用于确保共同关键字产生游戏独有的乐谱。
因此,有的seed会在整个游戏过程中固定下来,使游戏/开发者的音乐可重复,但与其他游戏/开发者的音乐不同,而其他seed可以是随机的,或者可能是基于游戏状态的算法生成。例如,seed可以基于位置值,所以产生的音乐是特定于位置的,并且响应所选的关键字。
通过这种方式,生成的音乐可以是可重复的,但对于游戏开发者、游戏名称、游戏位置或游戏状态(的其他方面来说是独一无二的。人工智能本身可以通过seed输入进行训练,以了解它们对输出的影响程度。
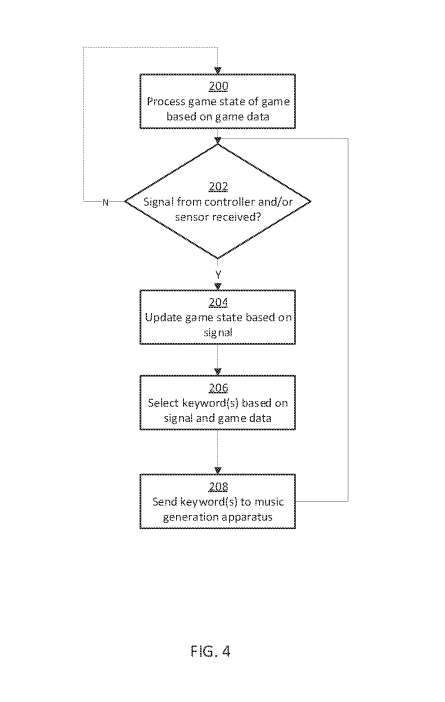
图4显示由上述娱乐设备15执行的流程图。
所述方法包括处理游戏的游戏状态的步骤200。在步骤202中,娱乐设备任选地确定是否从控制器和/或传感器接收到信号。如果没有接收到这样的信号,则返回到步骤200。如果已经接收到这样的信号,则基于信号更新游戏状态的步骤204。
另外,游戏状态可能在任何事件中更新,例如由于游戏中非玩家角色的行动。在步骤206中,基于信号和/或游戏数据选择一个或多个关键字。在步骤208中,将所选的一个或多个关键字发送到所述音乐生成设备。
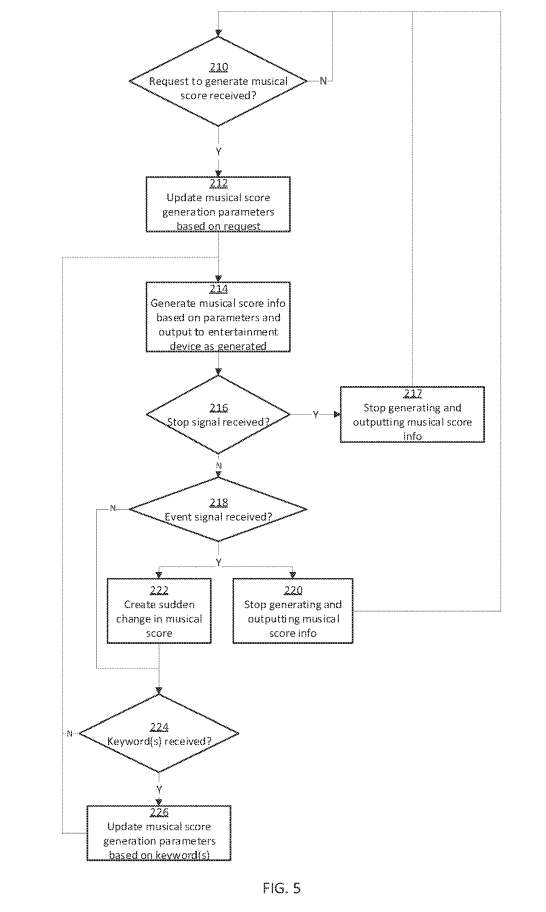
图5示出由上述音乐生成设备108执行的流程图。
在步骤210中,确定是否已接收到生成乐谱的请求。当确定已经接收到这样的请求时,基于请求更新一组乐谱生成参数的步骤212。
在步骤214中,音乐生成设备开始基于所述参数生成指示乐谱的信息,并在生成乐谱时输出指示乐谱的信息。
在步骤216中,确定是否已接收到停止信号,信号指示指示乐谱的信息的生成应停止。例如,这样的信号可以由娱乐设备发送到音乐生成设备,以响应游戏暂停或静音,或响应游戏内事件。
当确定已接收到停止信号时,停止或暂停生成并输出指示乐谱的信息的步骤217。然后,返回到步骤210,并等待接收到进一步的请求或指令。另一方面,如果确定尚未接收到停止信号,确定是否已接收到事件信号218。
在没有接收到事件信号的情况下,确定224是否已接收到一个或多个关键字。如果有,则根据关键字更新用于生成指示乐谱的信息的参数,并且返回到步骤214。
当接收到事件信号时,对于音乐生成设备如何响应有不同的选项。例如在步骤220中,音乐生成设备通过停止/暂停指示乐谱的信息的生成和输出来响应事件信号,从而使娱乐设备可以切换到播放与事件相关的一些预先录制的内容。
然后,回到步骤210。或者,在步骤222中,在乐谱中创建一个突然的变化,并且方法继续步骤224。
可以在响应不同关键字的输出之间流畅地切换乐谱。因此,可选地对关键字之间的常见转换进行人工智能训练,并且可选地在其输入中包括当前关键字和一个或多个前面的关键字,以为这种转换提供情景上下文。
所以,AI可能会根据“草地”和“洞穴”等关键词进行训练,从而为每种环境生成独特的氛围音乐。随后,当用户离开草地进入洞穴时,AI训练在音乐输出之间切换。
AI可以通过这种方式进行训练,以获得常见的关键字序列,无论是针对个别游戏,还是更普遍的情绪、风格、节奏等,这样配乐就可以随着游戏展开和/或响应玩家的输入/反应而愉快地流动。
如前所述,关键字可以描述环境,但可以更普遍地描述游戏或用户状态的任何方面,这些方面可能被认为与生成响应性乐谱有关。因此,作为非限制性的例子,关键词可以描述一个或多个环境,情绪,非玩家角色的品质或用户可以看到或与之交互的其他对象,玩家游戏角色的品质和/或当前状态。
因此,对于游戏中的特定时刻,可以使用多个关键词来描述游戏状态的突出方面。
人工智能可以根据关键字和相应的示例音乐进行训练。训练同时可能包括一个或多个随机seed输入以用于改变输出,并且在训练期间AI学习到seed与示例音乐无关,但实际上是输入中的噪点。同样,训练可以包括一个或多个先前的关键字输入,以训练AI进行常见的音乐过渡。
在游戏过程中,游戏状态可能会被适当的关键词标记,作为音乐生成设备的重要输入。例如,地点、NPC、对象、用户角色等都可以使用上述关键词进行标记。
图4和5分别说明可由娱乐设备15和音乐产生设备108执行过程的具体示例。但更一般地,娱乐设备可以执行包括以下步骤的方法:
根据游戏数据和与玩游戏的用户相关的动作和/或条件处理游戏的游戏状态;
在游戏处理过程中,根据与用户相关的一个或多个动作和/或条件以及游戏状态,选择一个或多个用于生成游戏乐谱的关键字。
另外,所述音乐生成设备执行的方法一般包括以下步骤:
接收生成游戏乐谱的请求;接收娱乐设备在游戏处理过程中输出的一个或多个关键字,其中一个或多个关键字指示与用户玩游戏和游戏状态相关的一个或多个动作和/或条件
作为对请求的回应,开始生成指示游戏乐谱的信息
响应接收到的每一个或多个关键字,更新生成的信息表示乐谱依赖于该关键字。
相关专利
:
Sony Patent | Generating a musical score for a game
名为“Generating a musical score for a game”的索尼专利申请最初在2024年2月提交,并在日前由美国专利商标局公布。