
(
映维网Nweon
2024年07月18日
)对于MR,在第一个情景中显示的内容可能不适用于第二个情景中。例如,适用于静态坐姿的计时器表示模式和输入模式可能不适合自行车骑行。
所以在名为“Method and device for dynamic sensory and input modes based on contextual state”的专利申请中,
苹果
就提出了一种根据情景状态来动态选择感官和输入模式的方法。
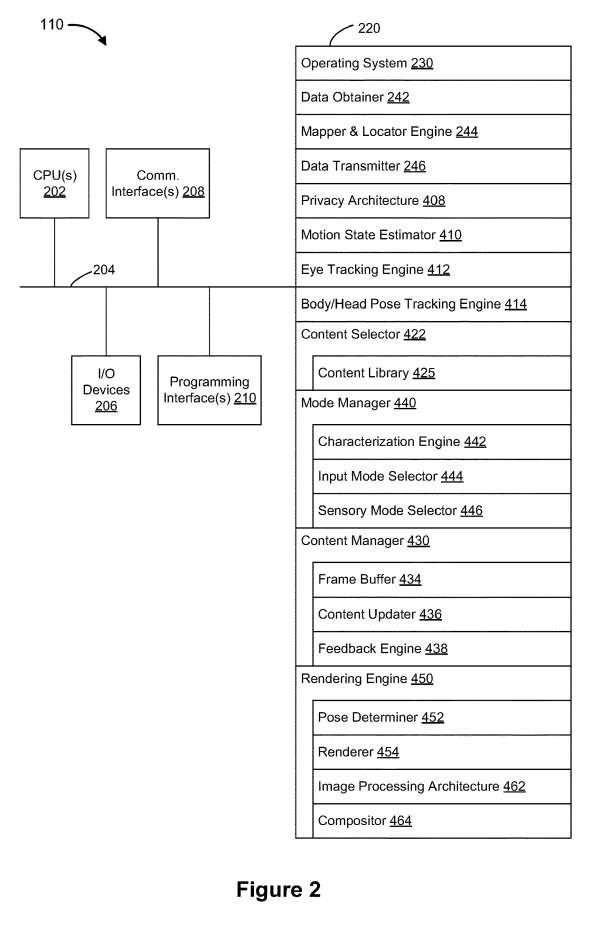
图2示出了控制器110的框图。
映射器和定位器引擎244配置为映射物理环境105并追踪至少电子设备120或用户150相对于物理环境105的位置/位置。
数据发送器246配置为将数据传输到至少电子设备120和任选的一个或多个其他设备。隐私架构408配置为摄取数据并基于一个或多个隐私过滤器过滤用户信息和/或识别数据中的信息。运动状态估计器410配置为基于输入数据获取相关联的运动状态向量411。
眼动追踪
引擎412配置为基于输入数据获得的眼动追踪向量413,并随时间更新眼动追踪向量413。身体/头部姿态追踪引擎414配置为基于输入数据获取姿态表征向量415,并随时间更新姿态表征向量415。
内容选择器422配置为基于一个或多个用户请求和/或输入而从内容库425选择XR内容。内容库425包括多个内容项。
模式管理器440配置为基于表征向量443选择一组输入模式445和表示模式447。模式管理器440包括表征引擎442、输入模式选择器444和感官模式选择器446。
在一个实施例中,表征引擎442配置为基于如图4A所示的运动状态向量411、眼动追踪向量413和姿态表征向量415中的至少一个来确定/生成表征向量443。表征引擎442同时配置为随时间更新姿态表征向量443。如图4B所示,表征向量443包括运动状态信息4102、注视方向信息4104、头部姿态信息4106A、身体姿态信息4106B、肢体追踪信息4106C、位置信息4108等。
基于表征向量443和与图4A所示的XR环境128相关联的XR环境描述符439,输入模式选择器444选择用于与XR环境128交互的当前输入模式集。例如,输入模式集可以包括手/四肢追踪输入、眼动追踪输入、语音命令和/或类似的至少一种。
感官模式选择器446配置为基于表征向量443为XR环境128中的XR内容选择当前表示模式。感官模式选择器446同时配置为基于表征向量443为XR环境128中的XR内容选择当前触觉反馈模式、声音反馈模式和/或类似的感官模式。
感官模式选择器446另外配置为基于用户输入、用户偏好、用户历史和/或类似,为XR环境128内的XR内容选择当前触觉反馈模式、声音反馈模式和/或类似的感官模式。
在一个实施例中,内容管理器430配置为管理和更新XR环境128的布局、设置、结构等,包括一个或多个XR内容、与XR内容关联的一个或多个用户界面UI元素等。
反馈引擎438配置为生成与XR环境128相关的感官反馈,例如视觉反馈(如文本或灯光变化)、音频反馈、触觉反馈等。
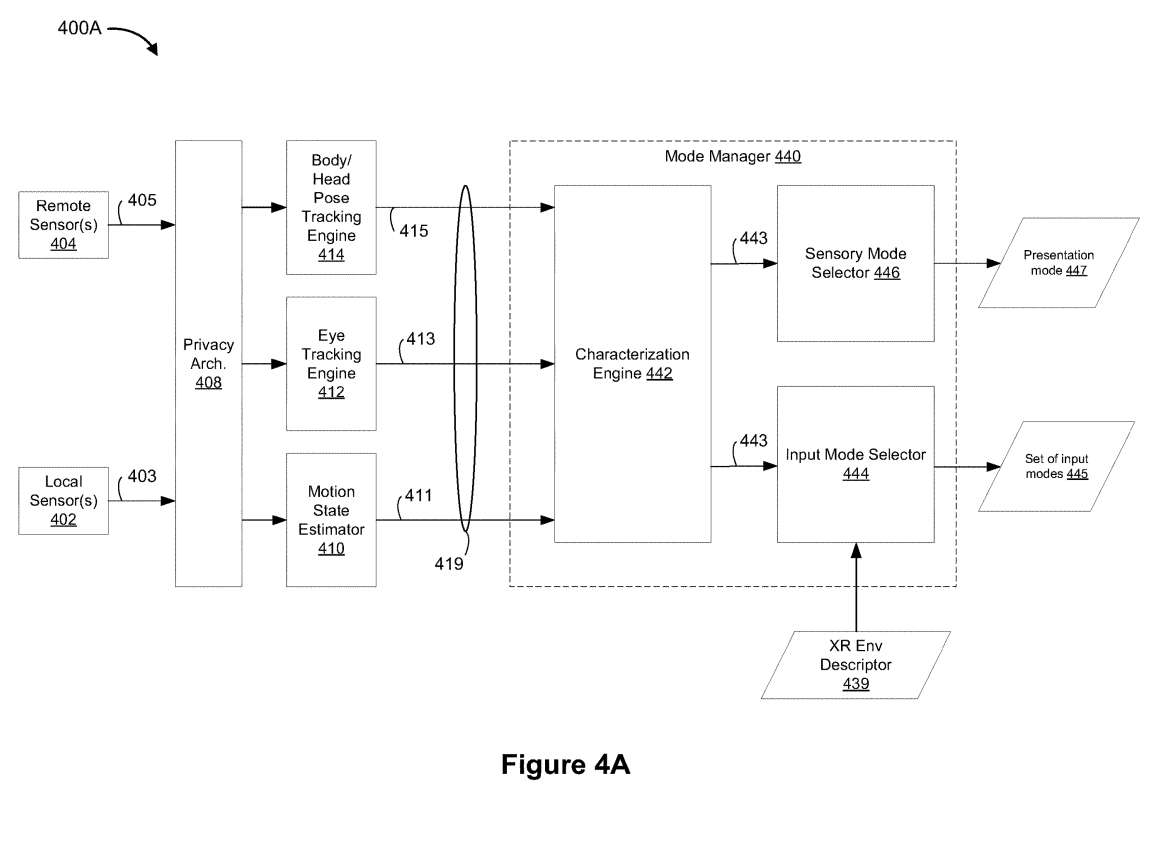
图4A是示例内容交付架构的第一部分400A。
如图4A所示,控制器110、电子设备120和/或其组合的一个或多个本地传感器402获得与物理环境105相关联的本地传感器数据403。例如,本地传感器数据403包括物理环境105的图像或其流、用于物理环境105的SLAM信息以及电子设备120或用户150相对于物理环境105的位置、用于物理环境105的环境照明信息、用于物理环境105的环境音频信息、用于物理环境105的声学信息、用于物理环境105的环境音频信息、用于物理环境105的声学信息。
类似地,如图4A所示,与物理环境105内的可选远程输入设备相关联的一个或多个远程传感器404获取与物理环境105相关联的远程传感器数据405。
隐私架构408摄取本地传感器数据403和远程传感器数据405。隐私架构408包括一个或多个与用户信息和/或识别信息相关联的隐私过滤器。隐私架构408包括可选入特征,其中电子设备120通知用户150正在监视哪些用户信息和/或识别信息以及如何使用用户信息和/或识别信息。
隐私架构408选择性地阻止和/或限制内容交付架构400A/400B或其部分获取和/或传输用户信息。所以,隐私架构408接收来自用户150的用户首选项和/或选择,以响应提示用户150进行相同的选择。
在一个实施例中,隐私架构408阻止内容交付架构400A/400B获取和/或传输用户信息,除非并且直到隐私架构408获得用户150的知情同意。
运动状态估计器410在隐私架构408之后获得本地传感器数据403和远程传感器数据405。运动状态估计器410基于输入数据获得运动状态向量411,并随时间更新运动状态向量411。
眼动追踪引擎412在隐私架构408之后获得本地传感器数据403和远程传感器数据405。眼动追踪引擎412基于输入数据获得眼动追踪向量413,并随时间更新眼动追踪向量413。
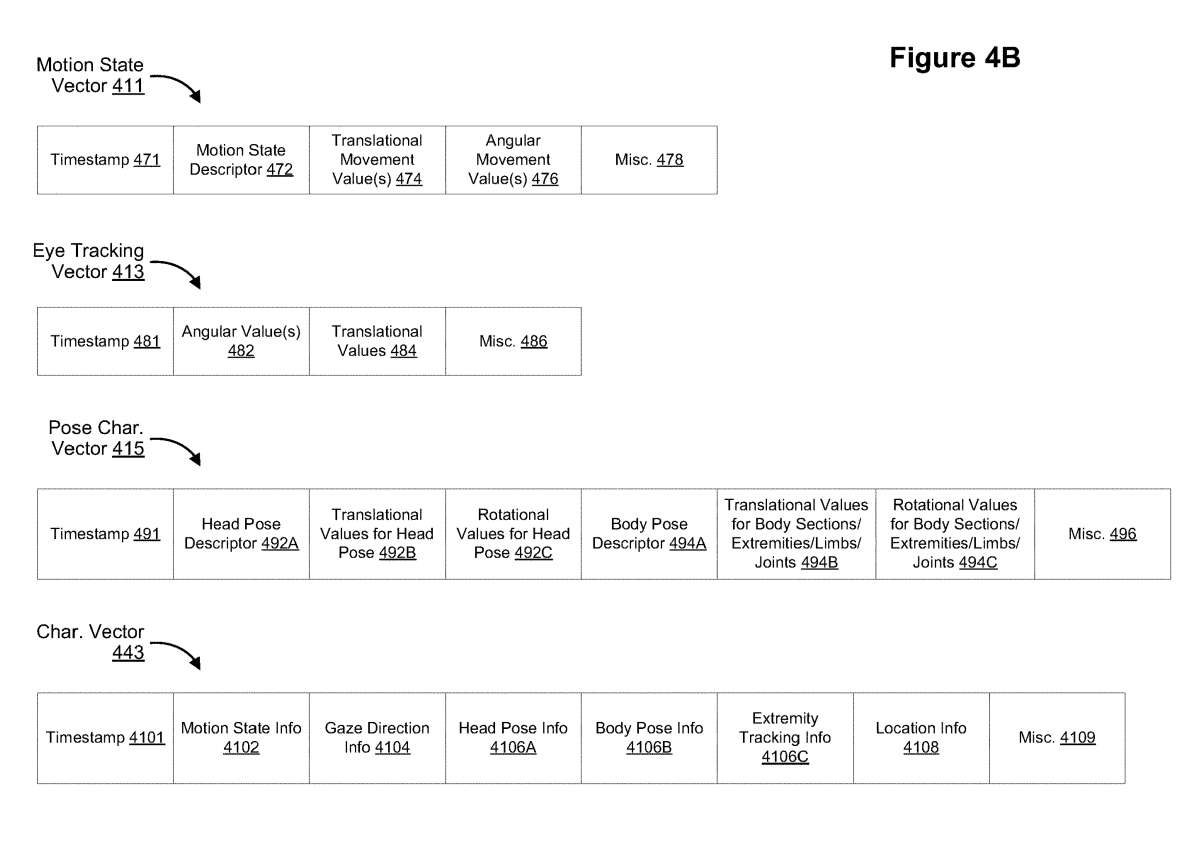
图4B同时显示了姿态表征向量415的示例数据结构。根据一个实施例,表征引擎442获得运动状态矢量411、眼动追踪矢量413和姿态表征矢量415。表征引擎442基于运动状态向量411、眼动追踪向量413和姿态表征向量415获得表征向量443。
输入模式选择器444基于表征向量443和与所述XR环境128相关联的XR环境描述符439来选择用于与所述XR环境128交互的一组当前输入模式445。例如,输入模式445的集合可以包括手/四肢追踪输入、眼动追踪输入、触控输入、语音命令和/或类似的至少一个。
在一个实施例中,感官模式选择器446基于表征向量443为XR环境128中的XR内容选择当前呈现模式447。例如,呈现模式447对应于媒体内容和/或XR内容的头部锁定呈现模式、身体锁定呈现模式、世界/对象锁定呈现模式、设备锁定呈现模式和/或类似的其中一种。
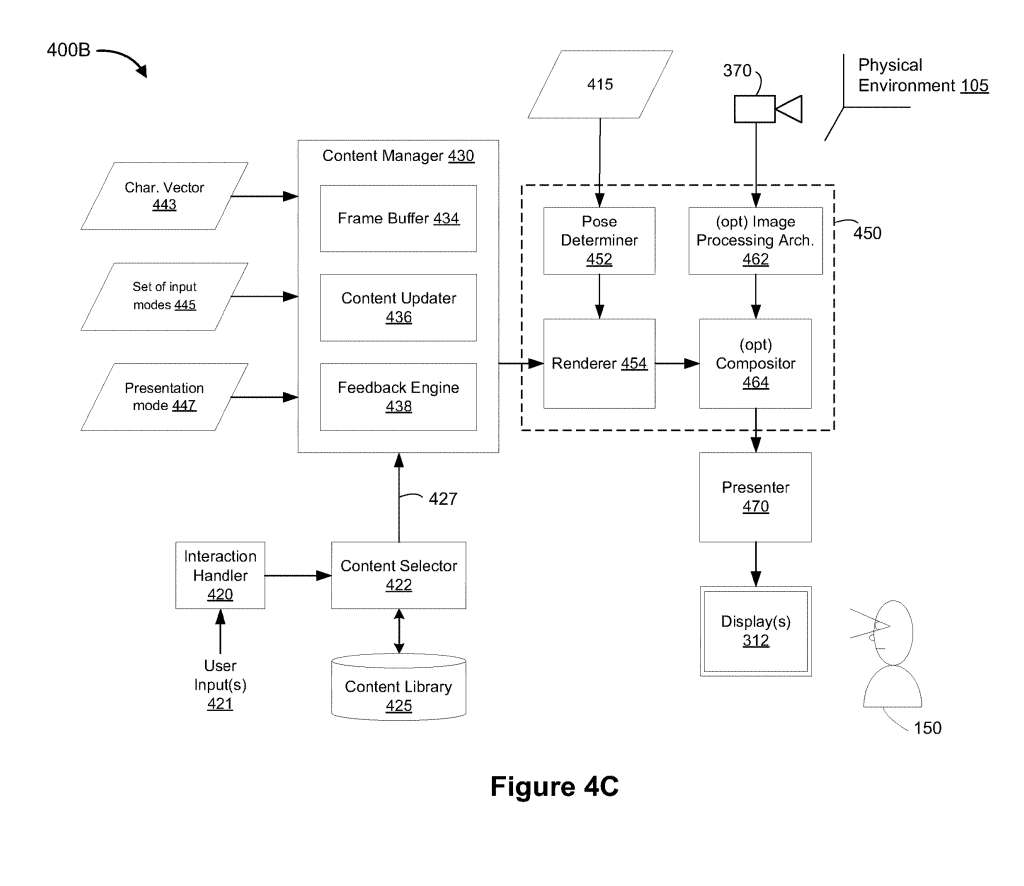
图4C是内容交付体系结构的第二部分400B。
交互处理程序420获取用户150提供的一个或多个用户输入421。例如,一个或多个用户输入421对应于从通过手/四肢追踪检测到的UI菜单中选择XR内容的手势输入、从通过眼动追踪检测到的UI菜单中选择XR内容的眼睛注视输入、从通过麦克风检测到的UI菜单中选择XR内容的语音命令等。内容选择器422基于一个或多个用户输入421而从内容库425中选择XR内容427。
在一个实施例中,内容管理器430管理和更新XR环境128的布局、设置、结构和/或类似,包括基于表征向量443的一个或多个XR内容、与XR内容关联的一个或多个UI元素和/或类似物、所选的输入模式集445、所选的表示模式447。所以,所述内容管理器430包括帧缓冲区434、所述内容更新器436和所述反馈引擎438。
在一个实施例中,帧缓冲区434包括用于一个或多个过去实例和/或帧的XR内容、呈现的图像帧和/或类似的内容。内容更新程序436根据表征向量443、选定的输入模式445集、选定的表示模式447、与修改和/或操纵XR内容或VA相关的用户输入421、物理环境105内对象的平移或旋转运动等随时间修改XR环境128。
在一个实施例中,反馈引擎438生成与XR环境128相关的感官反馈,例如,视觉反馈、音频反馈、触觉反馈等。
姿态确定器452至少部分地基于姿态表征向量415确定电子设备120和/或用户150相对于XR环境128和/或物理环境105的当前camera姿态。渲染器454根据相对于其的当前camera姿态渲染XR内容427、与XR内容关联的一个或多个UI元素和/或类似的内容。
图5A-5L说明了内容交付场景的实例序列510-5120。
如图5A所示,在内容交付场景的实例510期间,电子设备120呈现包括虚拟代理VA 505和物理环境105的视频透视环境128。
在图5A中,XR环境128包括与第一呈现模式相关联的计时器小组件504A和与用于与XR环境128交互的当前一组输入模式相关联的文本框517。
例如,计时器小组件504A对应于文本、图像、图标、徽章、视频内容、体积/3D XR内容等。例如,与计时器小组件504A相关联的第一外观对应于椭圆形状、第一尺寸、第一颜色、第一亮度和/或类似。计时器小组件504A的第一呈现模式对应于世界/对象锁定呈现模式,其中计时器小组件504A锚定到物理环境105中的物理对象,例如微波炉516。
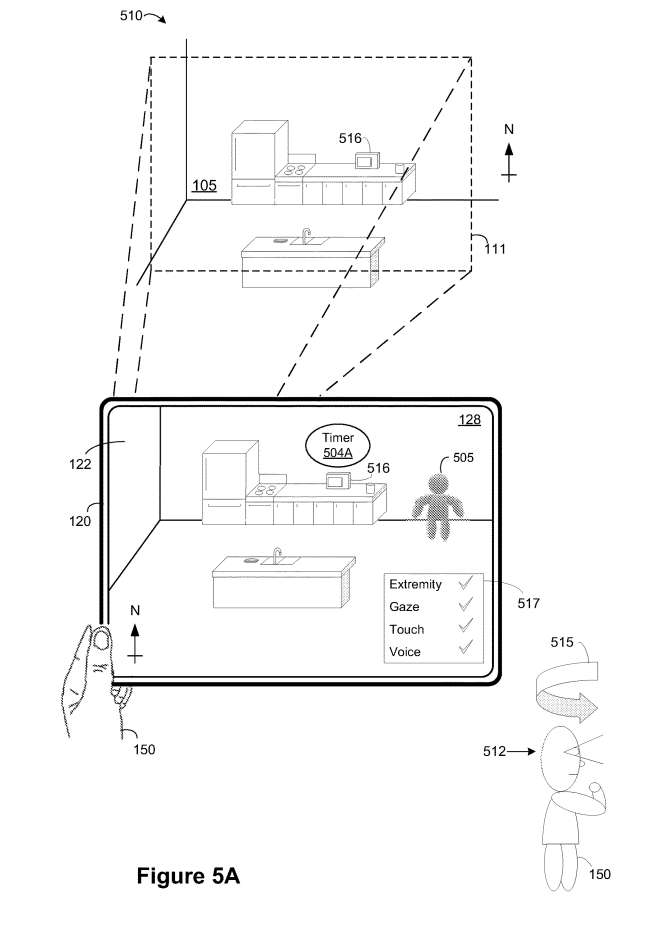
如图5A所示,与当前一组用于与XR环境128交互的输入模式相关联的文本框517表明,当前启用了以下输入模式:肢体追踪、眼动追踪、触碰和语音。
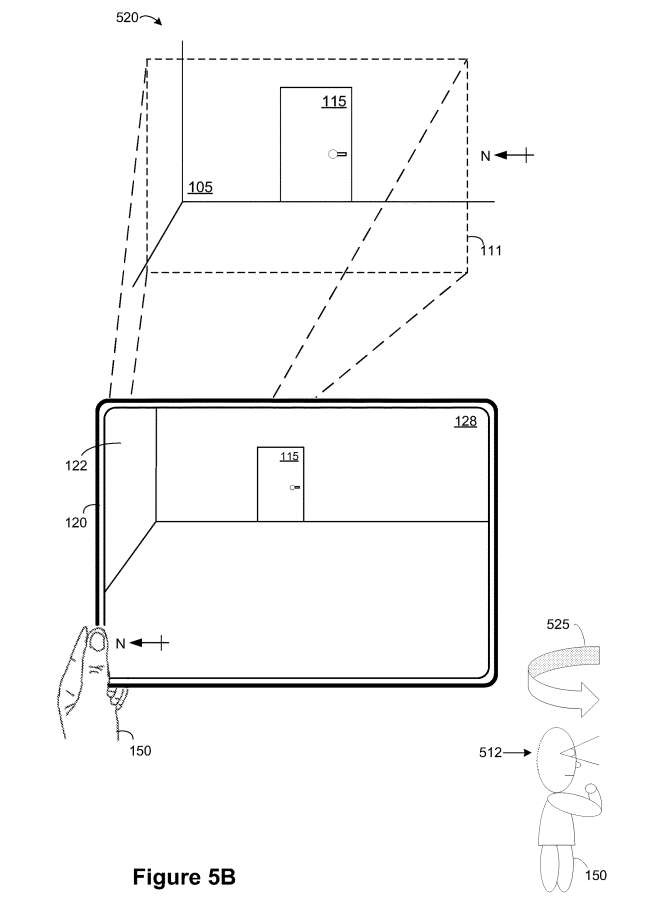
如图5B所示,在内容传递场景的实例520期间,电子设备120响应于检测图5A中90°顺时针旋转运动515,从面向东的方向呈现包含物理环境105的视频透视XR环境128。
在图5B中,XR环境128缺少VA 505和小组件定时器504A。如图5B所示,电子设备120检测到与900逆时针旋转运动525对应的电子设备120的camera姿势的变化。
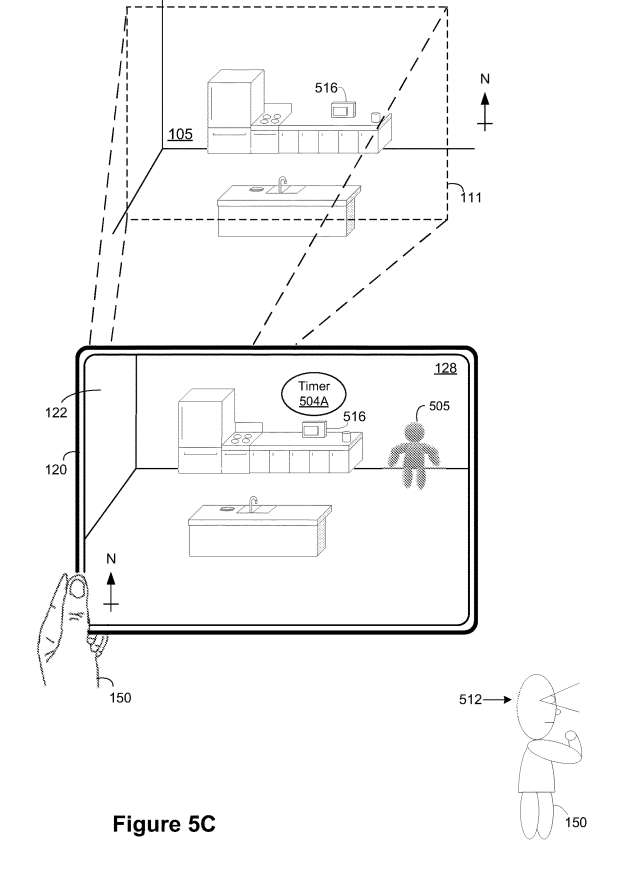
如图5C所示,在内容传递场景的实例530期间,电子设备120呈现包括VA 505和物理环境105的视频透视XR环境128。如图5C所示,XR环境128包括与第一呈现模式相关联的计时器小组件504A,其中计时器小组件504A与微波516相邻,类似于图5A。
在本例中,计时器小组件504A与世界/对象锁定表示模式相关联,以在用户150烹饪晚餐时帮助他/她。更具体地说,计时器小组件504A可以锁定在灶台,以帮助正确地定时烹饪灶台的食物或菜肴。
然而,如果用户150离开厨房,则电子设备120可以将计时器小组件504A更改为头部/显示锁定呈现模式,以便用户150在厨房外时可以追踪计时器小组件504A。
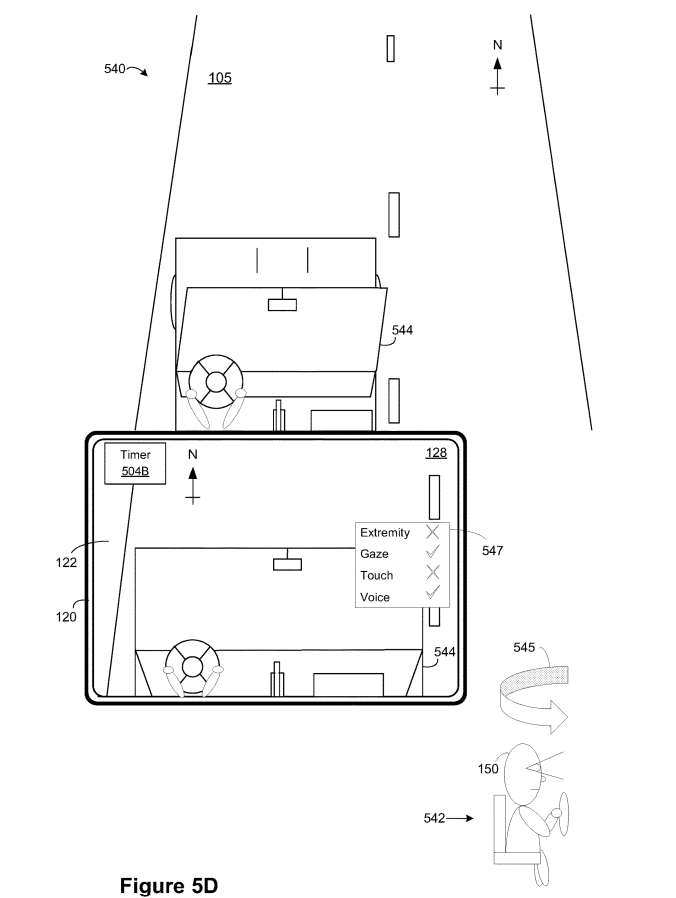
如图5D所示,在内容传递场景的实例540期间,电子设备120呈现包括物理环境10的视频透视的。在图5D中,XR环境128包括与第二呈现模式相关联的计时器小组件504B,以及与用于与XR环境128交互的当前一组输入模式相关联的文本框547。
计时器小组件504B对应于文本、图像、图标、徽章、视频内容、体积/3D XR内容等。例如,与计时器小组件504B相关联的第二外观对应于矩形形状、第二尺寸、第二颜色、第二亮度和/或类似。计时器小组件504B的第二表示模式对应于头部/显示锁定的表示模式,其中计时器小组件504B锚定到显示器122的预定义位置。
在图5D中,电子设备120的面向外部图像传感器的视场目前朝向北。例如,方向箭头可以在XR环境128中任意显示。如图5D所示,电子设备120检测到与90°逆时针旋转运动545对应的电子设备120的camera姿势的变化。
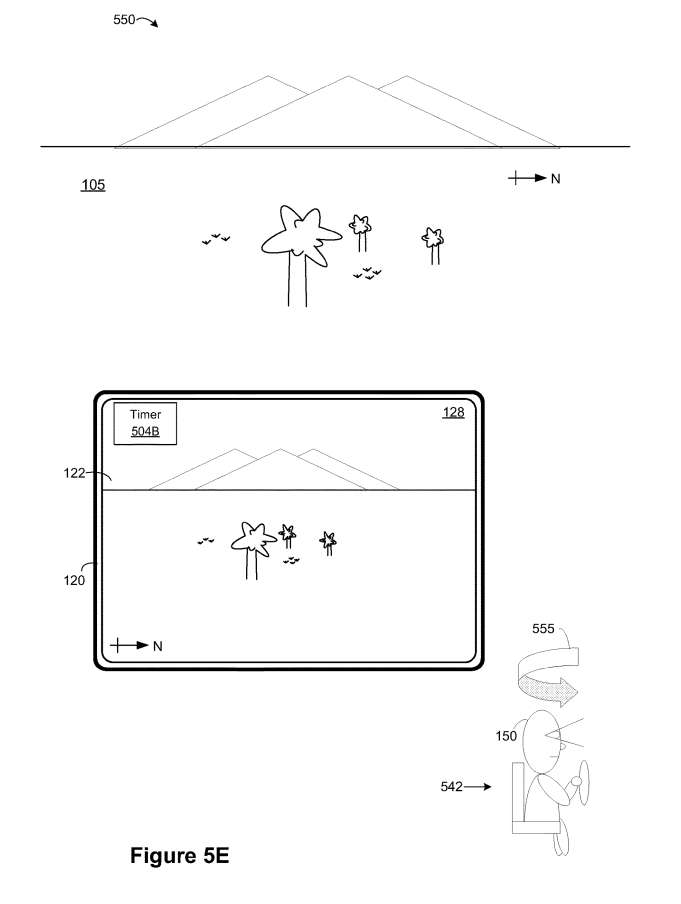
如图5E所示,在内容传递场景的实例550(期间,电子设备120响应于检测到图5D中90°逆时针旋转运动545,从面向西的方向呈现包含包括山脉和树木在内的物理环境105的视频透视XR环境128。
在图5E中,XR环境128包括与第二呈现模式相关联的小组件定时器504B。如图5E所示,电子设备120检测到电子设备120的camera姿势的变化。
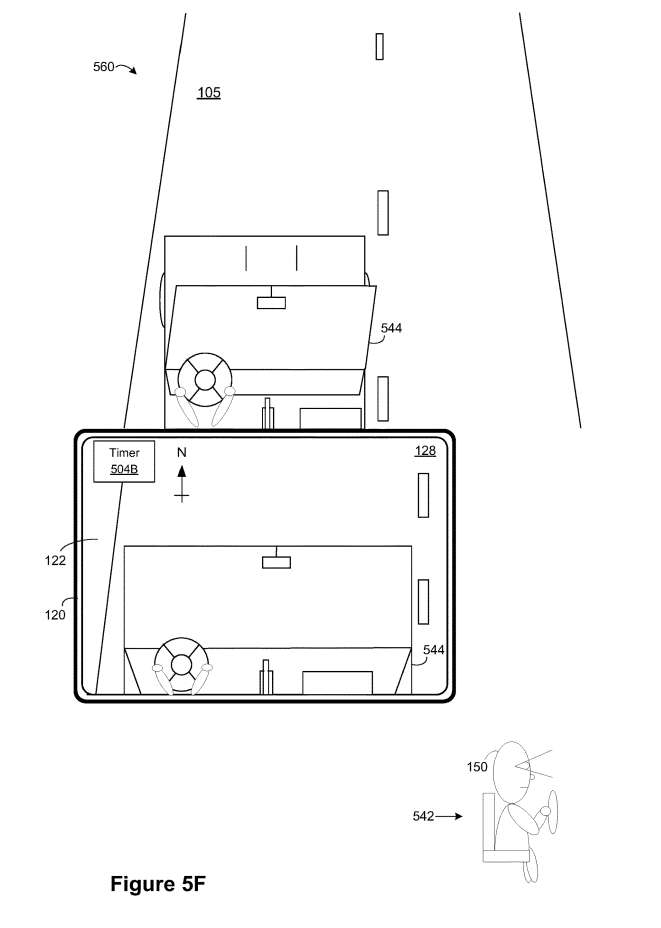
如图5F所示,在内容传递场景的实例560期间,电子设备120响应于检测图5E中的90°顺时针旋转运动555,呈现包括从面向北方向通过物理环境105的视频透视XR环境128。
在图5F中,XR环境128包括与第二呈现模式相关联的小组件定时器504B。在本例中,计时器小组件504B与头部/显示锁定的表示模式相关联,以便在用户150驾驶汽车544时不会妨碍他/她的视图。
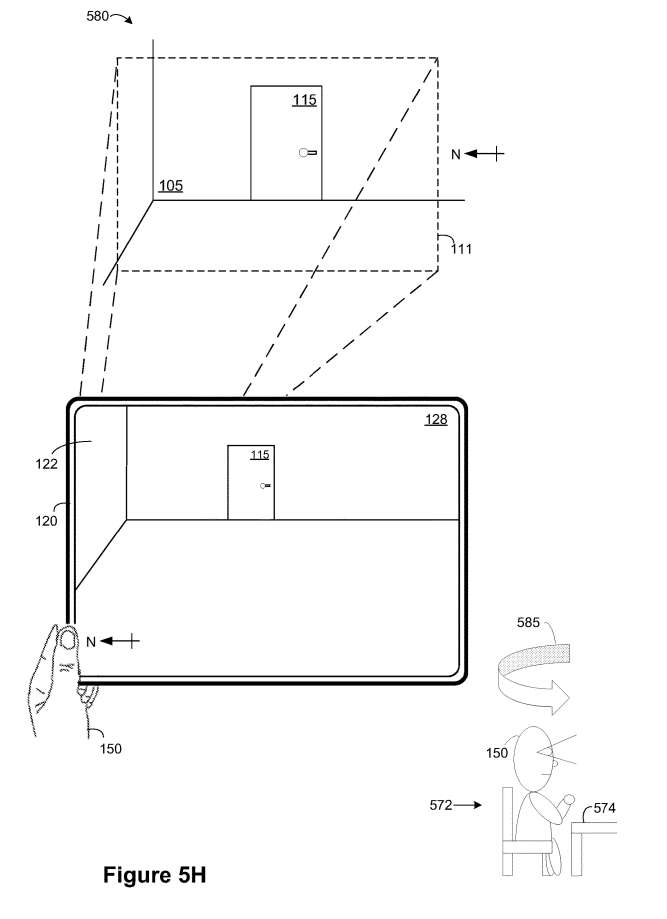
如图5G所示,在内容交付场景的实例570(期间,电子设备120从面向北的方向呈现包括VA 505的XR环境128和物理环境105的视频透视视图。
在图5G中,XR环境128包括与绘画573相邻的搜索结果576A,以及与用于与XR环境128交互的当前输入模式集相关联的文本框517。例如,搜索结果576A对应于文本、图像、图标、徽章、视频内容、体积/3D XR内容和/或与绘画573相关的搜索命令所产生的类似结果。
在图5G中,电子设备120的面向外部图像传感器的视场111目前朝向北。例如,方向箭头可以在XR环境128中任意显示。
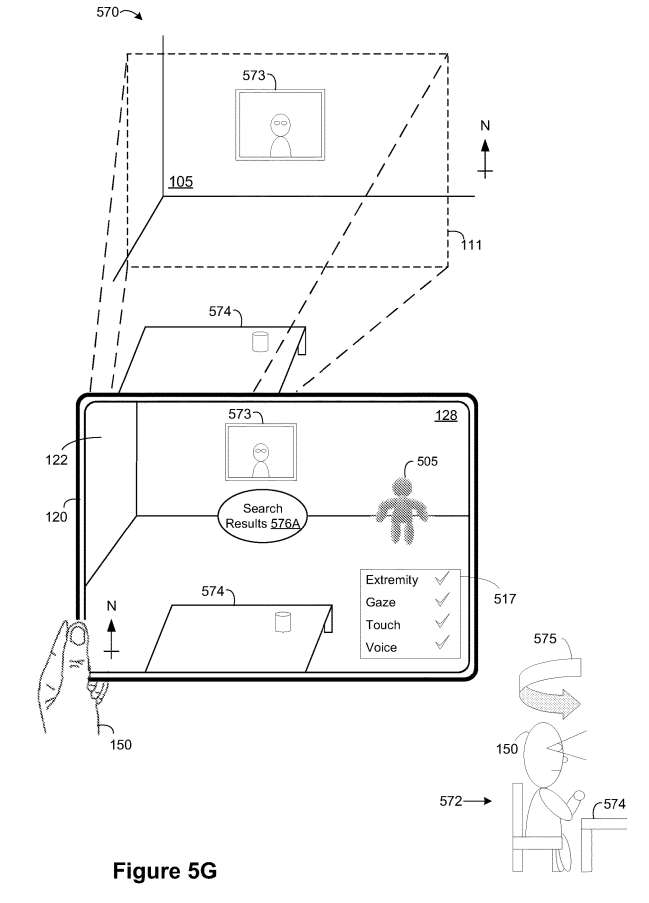
如图5H所示,在内容传递场景的实例580期间,电子设备120响应于检测图5G中90°顺时针旋转运动575,从面向东的方向呈现包含物理环境105的视频透视XR环境128。在图5H中,XR环境128缺少VA 505和搜索结果576A。如图5H所示,电子设备120检测到电子设备120的camera姿势变化。
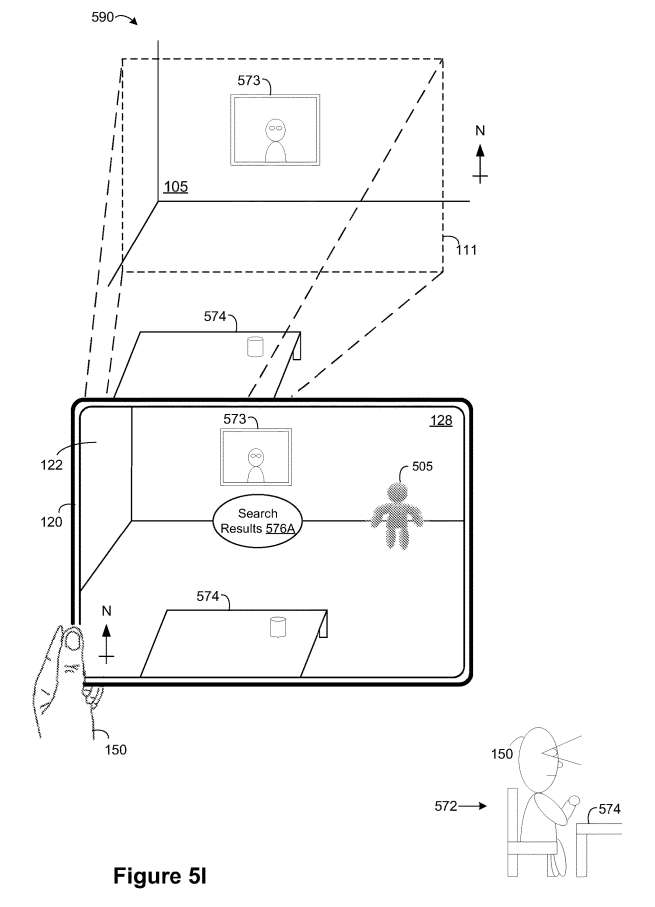
如图5I所示,电子设备120响应于检测图5H中90°逆时针旋转运动585,从面向北的方向呈现包含VA 505和物理环境105的视频透视XR环境128。如图5I所示,所述XR环境128包括与所述第一呈现模式相关联的搜索结果576A,其中所述搜索结果576A与所述绘画573相邻,类似于图5G。
在本例中,搜索结果576A与世界/对象锁定表示模式相关联,以便在用户150查看绘画573时教育他/她。然而,如果用户150带着绘画573离开房间,则电子设备120可以将搜索结果576A更改为头部/显示锁定的呈现模式,以便用户150可以在其选择的时间阅读搜索结果576A。
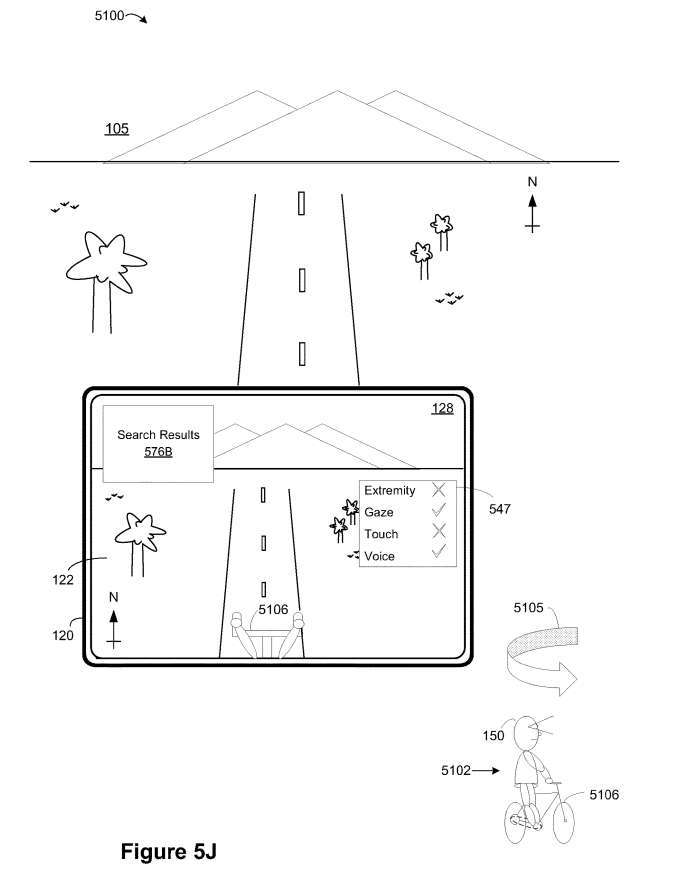
如图5J所示,XR环境128包括与第二呈现模式相关联的搜索结果576B,以及与用于与XR环境128交互的一组当前输入模式相关联的文本框547。
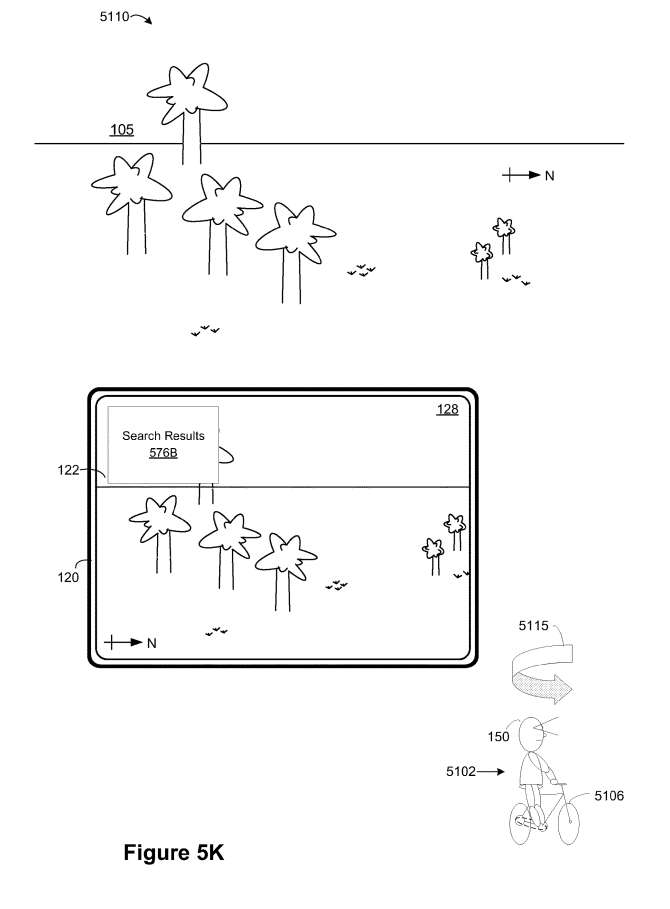
如图5K所示,电子设备120响应于检测到图5J中90°逆时针旋转运动5105,从面向西的方向呈现包含包括树木在内的物理环境105的视频传递的XR环境128。在
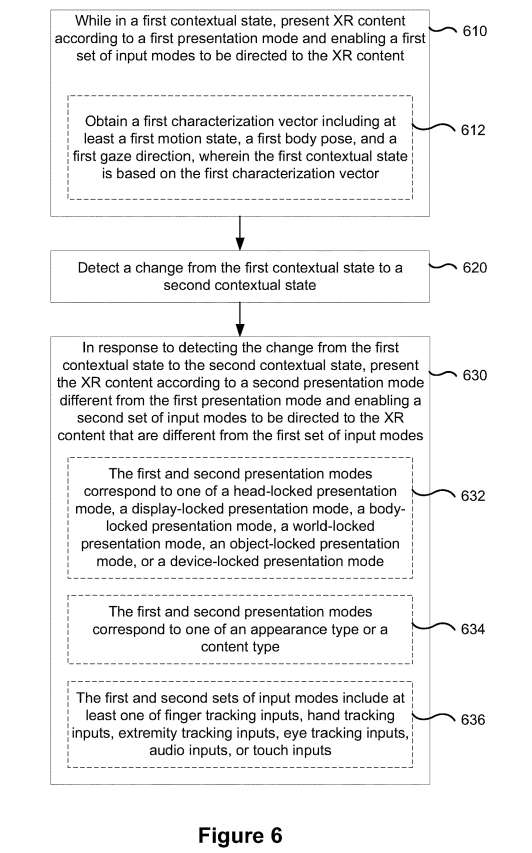
图6是基于当前情景状态与内容相关联的动态改变感官和/或输入模式的方法600。
如上所述,在第一个情景中以特定模式呈现的内容可能不适用于第二个情景中。所以,需要基于情景状态的变化来动态地改变相对于内容的感官和/或输入模式。
如610所示,在第一情景状态下,根据第一呈现模式通过显示设备呈现XR内容,并使第一组输入模式定向到XR内容。
作为一个示例,第一呈现模式对应于头部或显示锁定呈现模式,第一输入模式包括眼动追踪输入和音频输入,而第一情景状态对应于运输工具的操作,例如自行车、汽车等。所以在本例中,计算系统限制了对用户视场的干扰,提高了操作运输工具时的安全性。
如612所示,获得包括至少第一位置、第一运动状态、第一身体姿势和第一注视方向的第一表征向量。如图4A和4B所示,计算系统基于运动状态向量411(、眼动追踪向量413和姿势表征向量415获得表征向量443。
如620所示,检测从第一情景状态到第二情景状态的变化。
如630所示,为响应检测从第一情景状态到第二情景状态的变化,显示设备根据不同于第一视觉呈现的第二呈现模式呈现XR内容,并致使第二组输入模式定向到不同于第一输入模式的XR内容。
如632所示,第一和第二表示模式对应于头锁定的表示模式、显示锁定的表示模式、身体锁定的表示模式、世界/对象锁定的表示模式或设备锁定的表示模式之一。
如634所示,第一和第二表示模式对应于外观类型或内容类型之一。外观类型至少对应于预定义的大小、颜色、纹理、亮度等中的一种。内容类型对应于文本、图像、视频内容、体积/3D XR内容、音频内容、触觉反馈、小组件、通知、图标、徽章等。
如636所示,第一组和第二组输入模式包括手指追踪输入、手部追踪输入、四肢追踪输入、眼动追踪输入、音频输入或触摸输入中的至少一种。
为了响应检测从第一情景状态到第二情景状态的变化,方法600进一步包括呈现与第二情景状态相关的指示。
为了响应检测从第一情景状态到第二情景状态的变化,方法600进一步包括呈现与第二组输入模式相关的指示。
在一个实施例中,在根据第二表示方式呈现XR内容之后,方法600进一步包括:检测指向XR内容的用户输入;以及响应于检测所述用户输入并根据所述用户输入不对应于所述第二组输入模式之一的确定,放弃基于所述用户输入修改所述XR内容。
相关专利
:
Apple Patent | Method and device for dynamic sensory and input modes based on contextual state
名为“Method and device for dynamic sensory and input modes based on contextual state”的苹果专利申请最初在2024年1月提交,并在日前由美国专利商标局公布。