
(
映维网Nweon
2024年07月18日
)由于设备性能的限制,目前的Avartar系统通常无法传达细微的面部表情或情绪状态。所以在名为“Inferred shading”的专利申请中,
苹果
提出了一种利用基于机器学习的推断着色技术来生成Avatar。
为了生成逼真的Avatar,可以根据特定的环境点亮脸部的纹理。在一个或多个实施例中,可以训练推断着色网络来映射照明值、几何表情模型、头部姿势和camera角度,以产生根据与照明值相关联的环境照明的纹理。
在一个或多个实施例中,可以通过在具有各种照明变化的各种环境的图像训练自动编码器来获得照明值,从中可以确定表示场景中的照明和颜色的环境latent。这个过程包括训练阶段和应用阶段。
第一阶段涉及训练基于环境图像数据的环境自动编码器。捕获或以其他方式生成各种照明环境的一系列图像,以便在环境和场景中如何分布照明之间获得ground truth数据。在一个或多个实施例中,可以使用合成图像。
所以,环境自编码器可以提供将场景的图像映射到照明latent变量的照明编码器。在一个或多个实施例中,照明编码器可以附加到纹理解码器,纹理解码器可以进行训练以利用照明组件以及表情latent变量,以及有关camera角度和头部姿势的信息,以在特定照明条件下生成面部纹理。
类似地,可以将照明编码器附加到纹理解码器,其中纹理解码器训练成利用照明组件以及诸如对象姿态和/或camera角度的信息,以便在特定照明条件下生成对象的纹理。
第二阶段涉及到利用训练过的网络来生成一个Avatar,或者一个对象的其他虚拟表示。例如,可以使用多通道渲染技术生成Avatar。其中在多通道渲染过程中,将点亮的纹理贴图渲染为附加通道。作为另一个示例,用于特定表情和环境的照明纹理可以覆盖在基于照明纹理映射的主体的3D网格之上。
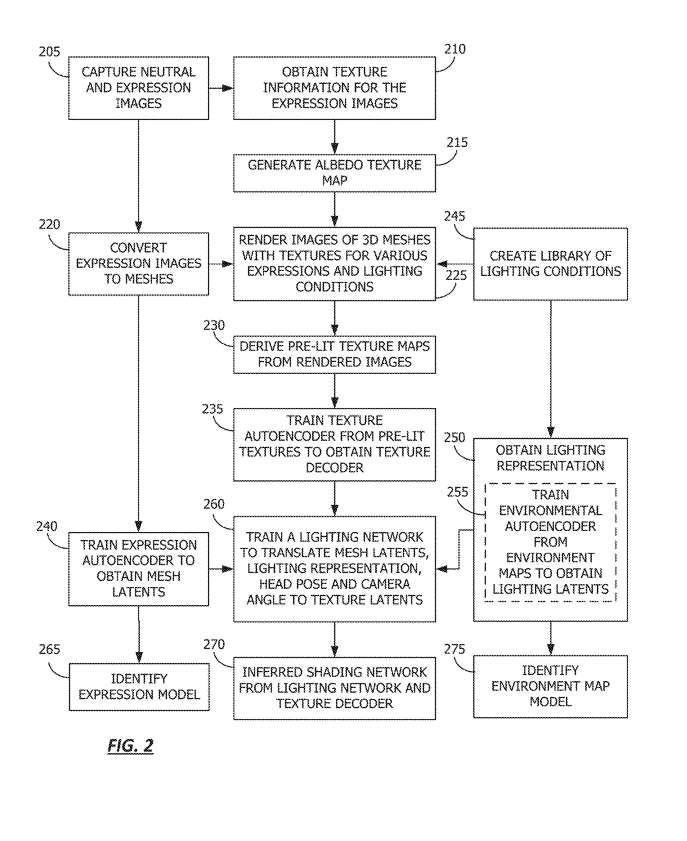
图2给出了从给定序列训练网格和纹理自编码器的流程图。
在一个实施例中,网格和纹理自动编码器可以从一个或多个用户的一系列图像中训练。
在210进行,训练模块122获取表情图像和中性图像的纹理信息。可以通过从主体的反照率图中提取光照分量来获得纹理信息。光照的偏移量可以从面部表情的反照率纹理图中计算。这样,可以获得与反照率图相关的表情图像的纹理。
在215,训练模块122生成纹理图,表示对象在完美照明下的纹理。可以为获得表情图像的每个主题生成反照率纹理图。纹理映射可以是一个2D映射,它表示主体的反照率纹理的颜色偏移。根据一个实施例,中性和表情图像可以由摄影测量系统或其他受控系统捕获,以确保人或其他主体的面部均匀照明。
返回到205,捕获一个中性和表情图像。在220,其中训练模块122转换为3D网格的表情图像。
可以在245创建照明条件库。训练模块122可以获取环境图像。环境图像具有不同的亮度和颜色。环境图像可以从各种地理区域获得,并且可以包括各种场景。可以通过增强捕获的环境图像来生成用于训练数据的附加环境图像,例如改变场景的视图,或修改场景的特征,例如亮度或旋转。可以从图像创建照明映射,并用于创建照明条件库。
在225,训练模块122渲染具有各种表情和光照条件的纹理的3D网格图像。在一个实施例中,图像可以由渲染软件渲染,该染软件可以采用3D网格和纹理,并根据所创建的照明条件库,使用点光源、指示环境中照明的环境地图等应用照明。另外,渲染图像可以在多光谱照明阶段中执行,其中每个光可以具有其自己的颜色和强度,并且可以单独控制,同时可以包括在照明条件库中。
在230,其中预照明纹理映射从渲染图像中派生出来。换句话说,与反照率纹理映射相反,反照率纹理映射指示主体在完全漫射照明下的纹理,预点亮纹理映射指示主体在225处渲染中使用的特定照明下的纹理。因此,纹理映射可以是2D映射,其指示基于特定照明的主体反照率纹理的颜色偏移。
然后,在235,训练纹理自动编码器。纹理自编码器可以使用来自230的预点亮纹理映射进行训练,以便再现纹理映射。这样,可以根据训练获得纹理latent。纹理latent可以是来自纹理latent向量的代表性值。另外,可以获得纹理解码器,以响应于训练纹理自编码器。
回到220,一旦从表情图像获得3D网格,流程图继续到240,其中3D网格表示可以用于训练表情网格自编码器神经网络。表情网格自动编码器可以训练为再现给定的表情网格。作为表情网格自编码器训练过程的一环,网格latent可以作为唯一网格的紧凑表示来获得。网格latent可以指代表图像中特定用户表达的latent向量值。
在一个实施例中,可以在245创建照明条件库。照明条件库可以从网络设备提供。照明条件库可包括具有各种特性的照明,例如方向、亮度等。
在250,获得照明表示。可以为在245创建的照明条件库中的各种照明映射确定照明表示。特定环境的照明可以用任何一种压缩的照明表示来表示。
在255,可以训练环境自动编码器以重新创建图像中的照明,例如照明条件库中的照明。因此,可以识别代表照明条件的潜在变量,例如亮度和颜色。
在260,其中一个照明网络训练来转换240的网格latant。在270,训练模块122有效地将来自260的照明编码器连接到来自235的纹理解码器。在一个实施例中,纹理解码器可以用作动态纹理模型,使得纹理模型可以基于网格latent输入、照明latent以及诸如头部姿势和camera角度等其他特征来估计纹理。
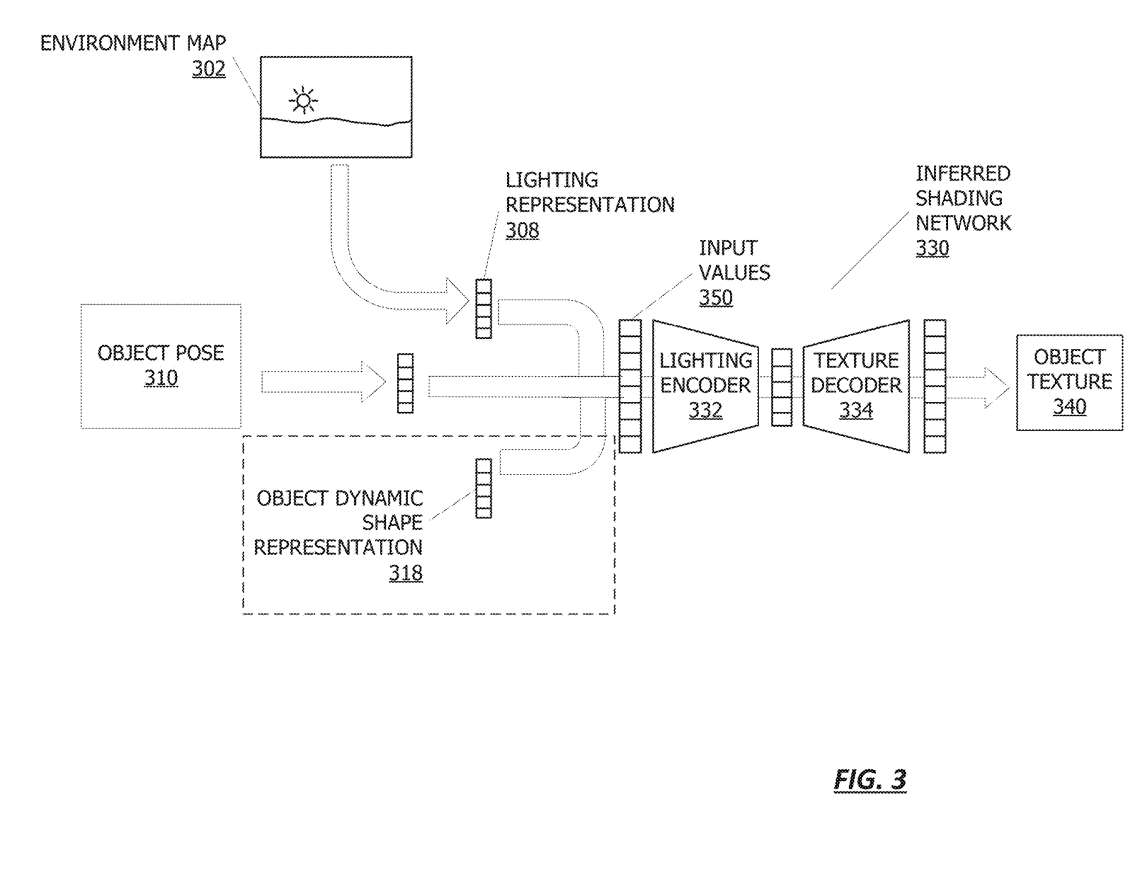
图3描述的流程用于训练推断着色网络以为点亮的对象提供纹理。
在302,接收一个环境映射,其中所述映射对应于要显示特定对象的环境。环境映射与具有特定照明的场景相关联。环境映射302的照明可以通过照明表示308来表示。照明表示308可以表示与场景中的照明相关的亮度、颜色和/或其他特征,并且可以是环境照明的任何种类的紧凑数字表示。
在一个实施例中,对象姿态310的输入到照明编码器322中。所述对象姿态310可以对应于所述推断着色网络330训练的对象。姿态可以表示为一组六个值,表示平移和旋转值,或可以是姿态的任何其他表示。根据一个实施例,所述对象可以是刚性或非刚性对象。
在刚体物体的情况下,刚体物体的几何形状可能“烘培”到推断的着色网络中,或者由推断着色网络忽略,因为形状不会改变,纹理可以简单地覆盖到对象的已知几何形状。
在非刚性对象的情况下,可以将对象的几何形状包括为对象动态形状表示318。对象动态形状表示318可以包括可以改变的对象的几何形状的表示。
所推断的着色网络330可包括附加到纹理解码器334的照明编码器332,所述纹理解码器334训练成读取输入值350以产生物体纹理340。照明编码器332可以将输入值350转换为纹理latent,纹理解码器334可以从中渲染对象纹理340。
根据一个实施例,可以将对象纹理340覆盖到对象的3D几何表示上以生成虚拟对象,使得虚拟对象看起来由环境地图302的照明照亮。
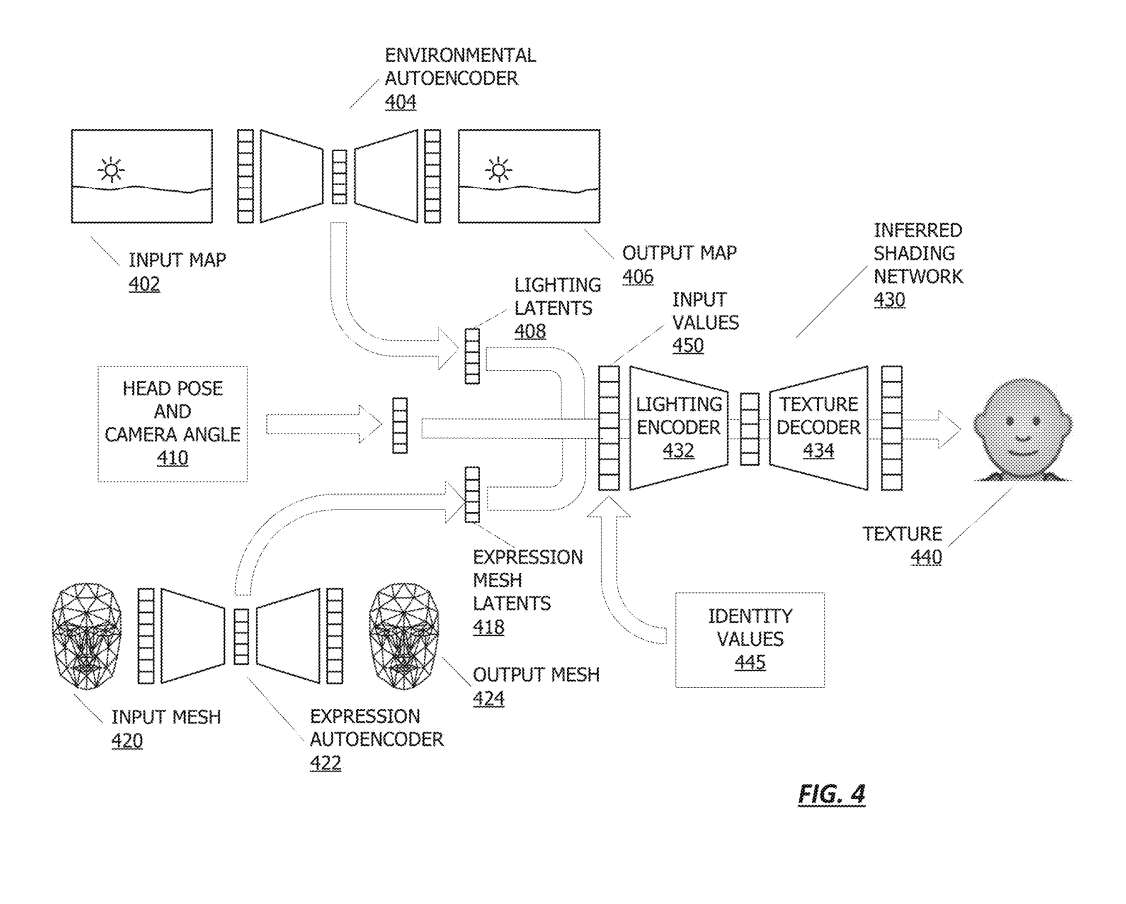
图4描述的流程图说明了训练推断着色网络以提供用户和环境之间的映射以及用于用户的照明纹理。
环境自动编码器训练来压缩和重新创建环境的图像时。因此,环境自动编码器404接受输入环境映射402并重新创建输出环境映射406。所训练的自编码器的副产品之一是,所述环境地图402的压缩版本包括照明latent408,其包括一组表示所述输入环境映射402的照明的值。例如,照明latent408可以表示与场景中的照明相关的亮度、颜色和/或其他特性。
所述流程图同时包括表情自编码器422,其接受表示在所述一系列帧中呈现的面部表情的输入网格420。在一个实施例中,面部表情可以通过获得与面部几何相关联的latent变量来确定。
在一个实施例中,照明表示308与头部姿势和camera角度410的表示一起输入到照明编码器322中。头部姿势和camera角度410可以分别表示,例如作为一组六个值,表示平移和旋转值,或者可以是头部姿势和camera角度的任何其他表示,例如组合表示。
根据一个实施例,推断着色网络430可以针对唯一的个体进行训练,或者可以训练成处理多人。在训练推断着色网络430处理多人的情况下,可以获得唯一标识要为其创建Avatar的人的身份值445。作为示例,返回到图2,照明网络可以对来自多个人的表情图像进行训练。身份值445可以指示个体的唯一性。
照明latent408、头部姿势和camera角度410、表情网格latent418和(可选)身份值445可以组合为照明编码器432的输入值450。在一个实施例中,各种输入可以相互加权或校准。作为示例,照明表示408可以由33个值组成,而独享姿态可以由12个值组成,并且表情网格latent可以由另外28个值组成。可以对组合值进行规范化,以防止各种值的过度表示或不足表示。
推断着色网络430可以包括附加到纹理解码器434的照明编码器432,纹理解码器434训练为读取输入值450,并且可以包括代表用户的纹理440。然后可以将纹理440应用于3D网格,并且所产生的Avatar可以显示在由输入环境映射402表示的环境中,使其看起来好像它由环境映射402表示的环境中的照明所照亮。
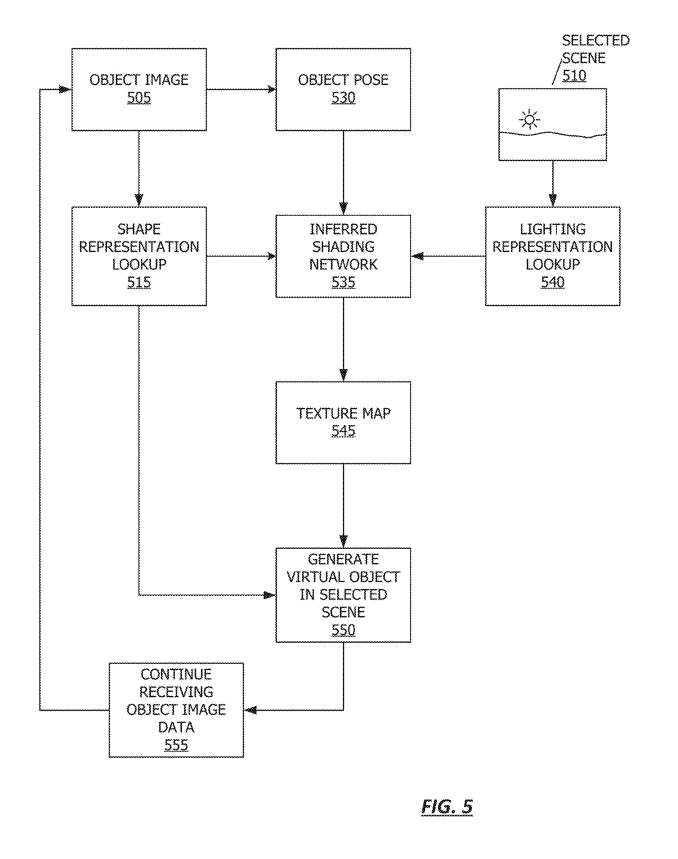
在图5的流程图,利用推断着色网络535渲染虚拟对象。根据一个实施例,虚拟对象可以通过客户端设备175的Avatar模块186来呈现。
在505,由虚拟对象表示的对象姿态是从对象图像确定。在接收到对象图像后,Avatar模块186在515执行形状表示查找。
在530,Avatar模块186决定对象的姿势。姿势可以基于客户端设备175接收的数据传感器获得。
在510,选择或确定选择的场景。可以为所请求的场景执行照明表示查找540。照明表示可以用各种方式表示。然后,推断着色网络535可以利用对象姿态、形状表示和照明表示来生成纹理映射545。
在550,其中Avatar模块186利用纹理映射,形状表示和确定的对象姿态渲染虚拟对象。虚拟对象可以以多种方式呈现。例如,2D纹理图可以作为多通道渲染技术中的附加通道进行渲染。作为另一个示例,虚拟对象可以使用包含在为虚拟对象渲染的照明数据中的纹理图进行渲染。
由于虚拟对象是实时生成,它可以基于对象的图像数据,或可以基于动态环境。在555,其中Avatar模块186继续接收对象图像数据。然后在505重复流程图,同时连续接收新的图像数据。
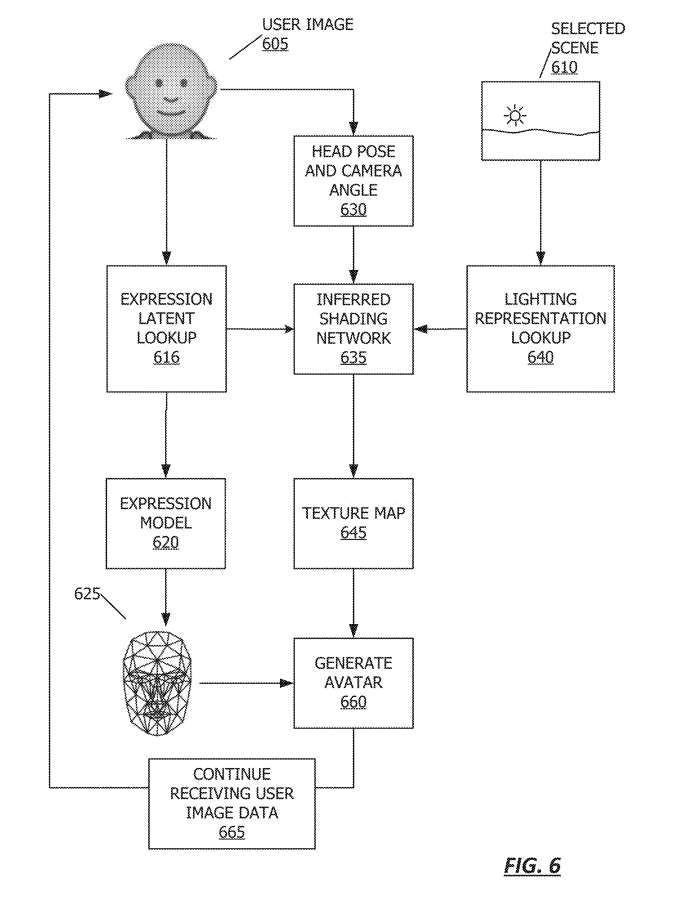
图6描述的流程图利用推断着色网络635渲染人的Avatar。根据一个实施例,可通过客户端设备175的Avatar模块186呈现所述Avatar。
从605开始,其中要由Avatar表示的表情是从用户图像中确定。在接收到用户图像后,Avatar模块186在616执行表情latent向量查找。可以从将图像数据映射到图像数据中表示用户的网格的三维几何信息的表达式模型中获得表情latent向量。然后可以利用表情模型620来确定基于所述表情latent执行所述表达的用户的网格表示625。
在630,Avatar模块186在确定要由Avatar表示的表情时确定头部姿势和camera角度。根据一个实施例,可以基于客户端设备175接收的数据传感器获得头部姿势。在610,选择一个场景。
在640进行照明表示查找640。在一个实施例中,环境中的照明可以使用球面谐波、球面高斯、球面小波等来表示。然后,推断着色网络635可以利用有关头部姿势和camera角度的表情latent、照明表示和数据,并生成纹理图645。
在660,其中Avatar模块186利用纹理映射渲染Avatar。角色可以以多种方式呈现。由于虚拟对象是实时生成,它可以基于对象的图像数据,或可以基于动态环境。在665继续,其中Avatar模块186继续接收对象图像数据,然后在605重复流程图,同时不断接收新的图像数据。
相关专利
:
Apple Patent | Inferred shading
名为“Inferred shading”的苹果专利申请最初在2024年3月提交,并在日前由美国专利商标局公布。